
In an era where semiconductor survival hinges on a single design win, FuriosaAI’s rebound from Meta’s rejection to LG’s multi-division adoption isn’t just remarkable, it’s geopolitical.
South Korea’s tech stack just got its own AI brain, and it's not coming from Silicon Valley.
From Shadows to Spotlight - RNGD’s Second Debut
When Meta pulled its $800 million commitment to FuriosaAI in late 2023, the narrative surrounding Korea’s homegrown AI chipmaker soured. Many in the industry saw it as a death knell for RNGD, Furiosa’s second-generation inference chip, pronounced “Renegade.”
But inside LG’s AI Research division, the withdrawal landed differently.
“We saw a different path for RNGD, one that wasn’t trying to chase NVIDIA, but rather sidestep it,” said a senior LG engineer involved in the evaluation.
Unlike general-purpose GPUs, RNGD was designed from day one for AI inference, optimized not just for speed but also for efficiency and deployment flexibility. Its architecture, built around TCP (Tensor Contraction Processor) cores, supported with a native FP8 arithmetic box, something NVIDIA only began supporting with H100.
LG began a two-year evaluation of Furiosa’s architecture in early 2023 with a small Exaone 3.5 deployment. But the chip’s performance quickly escalated interest. RNGD’s 4U air-cooled chassis required no liquid cooling, no exotic retrofits, just a practical, enterprise-ready footprint. This allowed LG to scale deployments seamlessly across research clusters and business units.
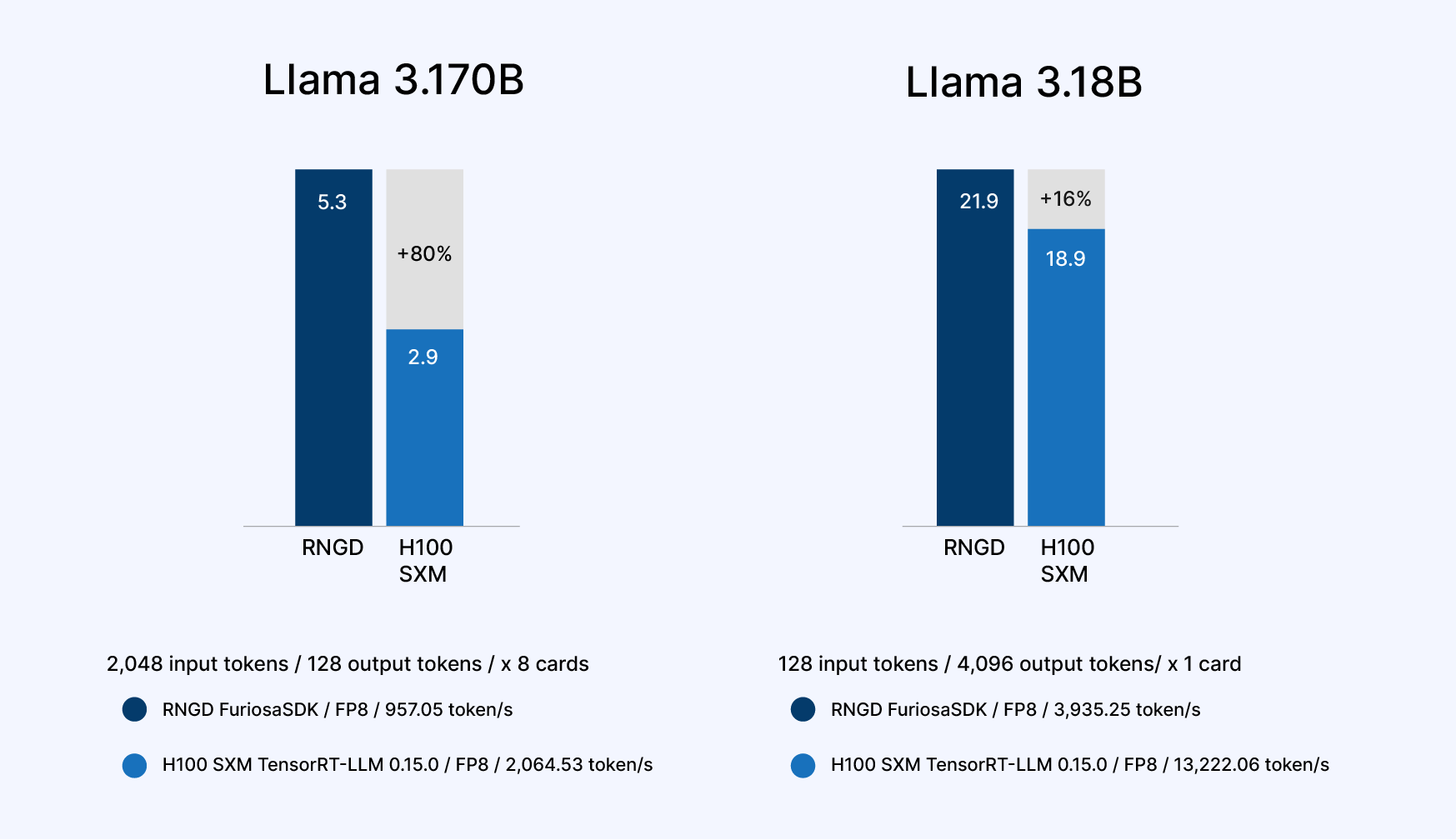
The result? RNGD now runs across LG’s sprawling divisions, Electronics, Finance, Telecom, and Biotech, handling everything from multilingual LLM inference to privacy-preserving edge AI. By early 2025, internal benchmarks showed RNGD outperforming the H100 by up to 3× in token throughput, with 39% lower power draw and 50% lower latency on transformer summarization.
This wasn’t just about swapping out NVIDIA. It was about redefining how and where inference could be done.
The TCP Architecture: Purpose-Built for Inference, Not Training
If most AI chips today are built like race cars, blazing-fast, overcooled, and overbuilt for the training track, then RNGD is something closer to a freight train: engineered for long-haul efficiency, not short bursts of benchmark speed. FuriosaAI didn’t just strip out unnecessary training hardware; it reimagined the core computational paradigm for inference-first performance.
At the heart of RNGD is the Tensor Contraction Processor (TCP), a custom-built compute engine that focuses exclusively on inference workloads. Unlike the general-purpose streaming multiprocessors (SMs) used in NVIDIA’s architectures, or the transformer engines added onto H100 and B200, the TCP design is optimized to sustain high matrix throughput without the memory and scheduling overhead that training demands.
The result is a massively parallel inference pipeline tuned for sustained token generation, not sporadic tensor backpropagation.
“TCP was never meant to compete with HBM-driven training rigs,” said one engineer close to Furiosa’s original chip team. “We knew we wouldn’t win on flops, so we went all in on inference latency, power efficiency, and memory-local operations.”
That commitment shows in the chip’s support for native FP8 arithmetic, a format still maturing in the GPU world but critical for squeezing performance out of transformer models without sacrificing accuracy. RNGD bakes FP8 support directly into its instruction set, offering faster execution paths than even NVIDIA’s late-stage integrations.
For LG’s workloads, especially multilingual LLM inference and fast summarization across low-power edge devices, FP8 provided the precision sweet spot.
Equally strategic was the decision to avoid high-bandwidth memory (HBM). Instead, RNGD relies on local DDR5 and SRAM buffers, allowing for reduced power consumption and far simpler system integration.
This trade-off, often considered a handicap in training-heavy environments, gave LG precisely what it needed: an inference chip that could slot into existing enterprise racks, scale horizontally, and run cold.
Furiosa’s compiler and runtime stack reinforce this lean approach. By tightly coupling the software stack to the TCP pipeline, Furiosa minimized scheduling overhead and enabled predictable, real-time performance across transformer, CNN, and tabular inference models.
This, according to LG’s benchmarking reports, contributed to RNGD’s dramatic gains in token throughput, per-watt efficiency, and model responsiveness compared to GPU-based deployments.
In essence, RNGD’s architecture didn’t just optimize for inference; it discarded everything that wasn’t.

FuriosaAI’s RNGD deployed in a 4U air-cooled server chassis, developed in partnership with LG AI Research. Designed for frictionless rollout, no liquid cooling required.
Inference in the Wild: How LG’s AI Stack Makes Use of RNGD
For LG, RNGD wasn’t simply a drop-in accelerator; it was a wedge that cracked open a new kind of inference strategy across the company’s sprawling digital landscape. From global consumer devices to enterprise R&D and regulated financial services, the chip didn’t just meet performance targets; it adapted to contexts where traditional GPUs struggled.

In LG Electronics, RNGD is being used to run on-device inference for multilingual voice assistants, tailored for ultra-low-latency response in products like smart TVs, appliances, and mobile interfaces.
These workloads prioritize quick token response and language switching without cloud roundtrips. The local deployment model, enabled by RNGD’s FP8 precision and DDR-based memory footprint, helped LG meet latency targets while eliminating external compute costs.
Meanwhile, in LG CNS (the company’s IT and consulting division), RNGD-powered clusters have taken on data summarization and document extraction workloads across telecom, insurance, and retail clients.
The chip’s low power draw and predictable latency proved vital for client deployments in tightly regulated data environments.
“We don’t need 8-GPU nodes for a transformer that summarizes legal clauses or call transcripts,” said a product lead at LG CNS. “What we needed was consistent inference performance on mid-sized models, and that’s where RNGD just outclassed everything.”
In finance and biotech, the focus shifted from throughput to privacy and compliance. LG Uplus and LG Chem both report early-stage uses of RNGD for privacy-preserving edge inference, particularly around federated learning and on-device pattern recognition.
Since RNGD doesn’t require cloud connectivity or offloaded model coordination, it becomes an asset in regulated pipelines where user data can’t leave local networks.
Even LG’s internal AI research group leaned into RNGD’s specific strength: running distilled LLMs at scale. With the rollout of Exaone 4.0, LG’s in-house foundation model, Furiosa’s RNGD became the default inference engine across internal R&D and production workloads. The chip’s FP8-native compute and tight integration with LG’s compiler stack made it an ideal match for compressed LLM variants optimized for real-time inference.
Internal benchmarks using models like LLaMA 3.1 showed RNGD consistently outperforming industry-leading accelerators under mid-scale deployment loads, especially when measuring tokens-per-watt, where it delivered over 2× efficiency gains.
But perhaps more critically, RNGD enabled LG to localize Exaone itself. Distilled versions were trained on culturally and linguistically distinct datasets and deployed directly to field clusters in Asia and Europe, all without needing hyperscale GPU infrastructure or cloud roundtrips.
|
Feature |
RNGD |
H100 SXM |
|
Technology |
TSMC 5nm |
TSMC 4nm |
|
BF16/FP8 (TFLOPS) |
256/512 |
989/1979 |
|
INT8/INT4 (TOPS) |
512/1024 |
1979/- |
|
Memory Capacity (GB) |
48 |
80 |
|
Memory Bandwidth (TB/s) |
1.5 |
3.35 |
|
Host I/F |
Gen5 x16 |
Gen5 x16 |
|
TDP (W) |
180 |
700 |
In short: RNGD didn’t just slot into LG’s AI roadmap, it redefined the architecture.
Exaone Meets RNGD: Custom Foundation Models, Deployed Differently
By the time LG rolled out Exaone 4.0 in Q2 2025, the company had fully internalized the strategic advantage of pairing a homegrown foundation model with a non-standard chip like RNGD.
Rather than chasing massive, centralized deployments, LG’s approach hinged on modular customization and localized inference, a strategy that RNGD made not only viable but scalable.
Exaone 4.0 itself is no monolith. Unlike typical foundation models that centralize training and inference into one massive stack, LG built Exaone as a modular, multilingual LLM family, adaptable across business domains.
RNGD’s FP8-native compute and Tensor Contraction Processor (TCP) cores were tailor-fit for running Exaone variants in edge clusters, R&D environments, and even semi-air-gapped corporate networks.
For LG Electronics, this meant deploying product-specific Exaone variants that could process user queries, troubleshoot logs, and contextual commands in real time, directly on-device or within local edge nodes.
In LG Finance and LG Uplus, RNGD accelerated internal copilots built on lightweight Exaone models that handle tasks from contract summarization to fraud anomaly detection, without needing access to external GPUs or exposing sensitive customer data to public clouds.
Even LG Chem found applications: researchers leveraged Exaone-RNGD pipelines for chemical property predictions and material science simulations, often using distilled transformer models fine-tuned on proprietary research corpora.
Because RNGD enabled low-latency batch inference without power-hungry infrastructure, simulations that once required off-site compute now ran inside in-house research labs.

RNGD specifications: 512 TFLOPS FP8, 48GB memory, 180W TDP. Built for power efficiency without sacrificing throughput.
What tied all these deployments together wasn’t just RNGD’s speed; it was ownership. Unlike GPU-based models often bound by cloud providers’ software and driver ecosystems, LG’s RNGD+Exaone stack offered full-stack control: firmware, scheduler, compiler, and model weights. That autonomy proved critical in highly regulated or IP-sensitive deployments.
As one LG AI Research scientist put it:
“With RNGD and Exaone, we stopped thinking in terms of ‘what NVIDIA will let us run.’ We started thinking in terms of what we actually need.”
This synergy between a custom-built chip and a purpose-trained model wasn’t just LG’s hardware-software co-design moment. It was a blueprint for regional AI infrastructure, rooted in local compute, local language, and sovereign data governance.
|
Model Type |
Seq Length |
Input Length |
Output Length |
TTFT (s) |
TPOT (ms) |
|
EXAONE 3.5 |
4K |
3072 |
128 |
0.347 |
16.96 |
|
1024 |
0.349 |
16.96 |
|||
|
32B (16 bit) |
32K |
30720 |
128 |
4.568 |
19.58 |
|
2048 |
4.562 |
19.54 |
Exaone 3.5 model performance benchmarks used during LG’s early testing phase with RNGD accelerators.
A Bet Beyond Meta
FuriosaAI’s comeback wasn’t orchestrated in Silicon Valley boardrooms or hyped through investor decks. It happened in clean rooms, air-cooled racks, and R&D labs where performance trumped pedigree. And LG wasn’t just a customer; it became Furiosa’s proving ground.
By mid-2025, LG had integrated RNGD across four of its largest verticals. The chip’s impact rippled through use cases as varied as material synthesis and on-device customer assistants, and in each, it didn’t just replace existing hardware; it rewired how inference workloads were conceived. LG’s internal reports cited RNGD’s 3× performance-to-watt edge over leading GPUs as a key reason for greenlighting multi-year, multi-division deployments.
At the same time, Furiosa began attracting attention from new enterprise and defence-aligned buyers in Japan, the Middle East, and Europe. RNGD wasn’t marketed as a GPU alternative; it was marketed as a sovereign inference accelerator, a core enabler of regional AI stacks that could sidestep U.S. export bottlenecks, reduce reliance on hyperscalers, and support language-specific model hosting.
LG’s bet on Furiosa was never just about FLOPS. It was about freedom. About owning the full AI pipeline, from silicon and scheduler to model and deployment surface. And in that bet, RNGD found its second debut not as a runner-up to NVIDIA, but as a reference model for what next-generation AI infrastructure could look like when designed on different terms.
As FuriosaAI quietly ramps production of its next chip, codenamed “RNGD-M” for early customers, the company is no longer chasing a cancelled USD 800 million deal. It’s chasing something far rarer in the semiconductor world: a second chance, delivered through first principles.




