
The data center is no longer just a room full of servers; it’s now a system built around the silicon that powers it. As AI accelerators surge in both scale and density, data centers themselves are reshaping. Analysts at Goldman Sachs project that global data center power demand could jump 165% by 2030, driven largely by AI workloads.
Meanwhile, global data center capacity is already growing at over 33% annually, fuelled by new facilities tailored to training and inference. At the same time, the systems pushing this shift the hardest, advanced AI racks, like those built around 72-GPU Blackwell NVL72, which compresses massive compute into a single high-density unit, pushing rack-level power densities to unprecedented levels.
The result? The most foundational design question in modern data centers is no longer “what chips can we host?”, it’s now “how do we build around the chip?”
Power Demand Is Reshaping the Room
As the AI boom intensifies, the physical infrastructure that houses it is under pressure. This isn’t a marginal uptick; these are facility-wide transformations.
Global Data Center Power Demand Forecast (2024–2030)
.jpg)
As the AI boom intensifies, the physical infrastructure that houses it is under pressure. This isn’t just higher consumption; it’s a fundamental reset in how facilities are planned and built.
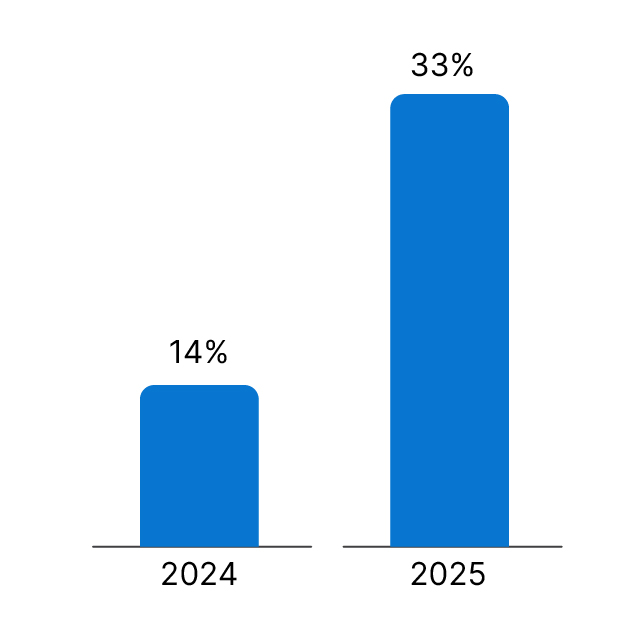
Operators are already observing the early signs of this shift. Liquid cooling adoption (especially in AI clusters) is expected to jump from around 14% in 2024 to 33% in 2025, a massive leap in just one year, one of the fastest thermal transitions the industry has ever seen.
Liquid Cooling Adoption: 2024 vs 2025
Much of this acceleration is driven by ultra-dense racks like NVIDIA’s GB200 NVL72 systems, which can draw 130-140 kW per rack, far beyond what air-cooled rooms were designed to handle.
But the shift goes deeper than cooling. High-bandwidth interconnects such as NVLink, InfiniBand, and emerging switchless topologies are becoming the default for GPU clusters, forcing a rethink of rack spacing, cable architecture, and room geometry.
Utilities, too, are scrambling to keep up. Grid upgrades that once took years now risk falling behind the chip roadmap itself. In several regions, power-delivery plans are being aligned directly with AI chip power envelopes rather than traditional per-rack estimates.
What used to be a stable data center build model is now fractured. Power, cooling, and silicon are no longer separate considerations; they are converging into a single architecture. And this convergence sets up the question that defines the next phase;
What technologies can carry data centers into this new thermal and power era?
When the Chip Starts Dictating the Room
In today’s AI arms race, it’s no longer enough to build around generic GPUs; chips themselves are being designed with data center architecture in mind. Take Blackwell NVL72, for example, its rack-scale design drives huge bandwidth (130 TB/s of NVLink) and high-power draw, which pushes facilities toward liquid cooling and denser power distribution.

But Blackwell is just the beginning. Over in Google’s world, TPU v5p comes in giant 8,960-chip pods, interconnected by a 4,800 Gb/s fabric, a level of scale that blows up both network and thermal design assumptions. Its high-bandwidth memory (HBM) and system-level pod architecture make efficient interconnects and cooling non-negotiable.
Meanwhile, AWS Trainium2, built for their Trn2 instances, delivers up to 83.2 petaflops using 64-chip UltraServers, with each chip feeding high-bandwidth memory (up to 6 TB HBM) across a custom NeuronLink interconnect.

By focusing on power efficiency rather than raw FLOPs, Trainium2 pulls facility design toward more moderate rack densities, but still demands precise power delivery.
Then there’s Meta’s MTIA family; tuned not for bleeding-edge training super-models, but for inference-heavy workloads in recommendation systems. They’re deployed at scale in Meta’s own data centers.
_v2.webp)
Meta claims its second-generation MTIA delivers up to 3.5× denser compute and 7× more sparse performance compared to v1. That shift allows Meta to design racks and power systems that don’t purely revolve around peak GPU performance, but around consistent, energy-efficient inference loads.
Together, these innovations don’t just preview the future; they force today’s data center builders to reconsider: Is the floor plan we’re building today even viable in a world where the chip sets the constraints?
Where the Industry Is Betting Big?
The shift toward chip-centric data center design isn’t theoretical anymore; it’s visible in every major hyperscaler’s roadmap. At AWS, the decision to build data centers around Trainium2 and Graviton4 has already begun reshaping internal layouts.
Amazon says its new Trn2 UltraClusters link tens of thousands of Trainium2 accelerators through a purpose-built fabric to “reduce network hops and eliminate performance bottlenecks.”
This changes how AWS allocates space: clusters are no longer arranged for general-purpose compute, but for inference and training blocks optimised around chip locality. It’s a subtle but profound restructuring inside their newest facilities.
Google is taking a different path. With TPU v5p deployed inside its AI Hypercomputer architecture, Google’s design emphasis has shifted toward massive pod-scale networks, with v5p pods reaching 8,960 chips connected through a 4,800 Gb/s interconnect.
This scale forces Google to build thermally predictable rooms where airflow, power feeds, and fabric switching are modelled as a single system rather than three independent layers.
Microsoft, meanwhile, has doubled down on liquid-readiness. The company confirmed that future Azure sites are being built with liquid as a baseline, driven largely by GPU clusters built around NVIDIA H100 and now Blackwell GB200.
For Microsoft, it isn’t just about supporting higher rack densities; it’s about placing cooling, power, and networking in the same design envelope as the chip roadmap they know is coming.
And then there is Meta, which has quietly become the most aggressive in tailoring infrastructure around its own silicon. With MTIA v2 powering large-scale recommendation workloads, Meta redesigned sections of its data centers for sustained, inference-heavy power profiles rather than the spiky loads typical of GPUs.
Across operators, the signal is the same: the era of one-size-fits-all data centers is ending. The largest players are now designing facilities according to their silicon strategies, not the other way around, and the differences in their chip roadmaps are beginning to express themselves physically in their buildings.
The Road to 2030: What the Next Five Years Really Look Like
The upcoming years look promising; the role of AI chips in data center design won’t be theoretical; it will be an architectural fact. Blackwell-class accelerators, Grace-powered nodes, and next-generation tensor ASICs will dictate everything from substation planning to thermal envelopes to the number of megawatts a campus can safely pull without overloading the grid. But the next five years won’t be defined by a single breakthrough. Instead, they’ll be shaped by a layered convergence of silicon, power, and operation.
Chip roadmaps are tightening the timelines for facility upgrades. Most operators once worked in seven-year refresh cycles; AI clusters now demand two-to three-year turns. This pace pushes liquid cooling beyond “early adoption” and into baseline engineering.
Even conservative operators tell analysts that immersion, cold plates, or hybrid loops will become standard for any rack pulling over 80-100 kW, a threshold that Blackwell NVL72 racks already exceed comfortably.
The power picture is equally non-negotiable. Grid interconnect queues are widening, forcing hyperscalers to build modular substations, on-site generation, and thermal-storage buffers just to keep capacity predictable.
Data centers that were originally designed around CPUs are being retrofitted around GPU-centric power envelopes, and in newer campuses, utilities are designing their distribution maps directly off the chip roadmaps of NVIDIA, AMD, and custom ASIC vendors.
By 2030, the most competitive data centers won’t simply “support” AI chips; they’ll be co-designed with them. Operators that treat silicon as the architectural starting point will gain the advantage: higher rack densities, better energy economics, and faster deployment of AI workloads.
The next generation of facilities won’t ask how to fit GPUs into a data center. They’ll ask how to build the data center around the GPU.




