Most of us don’t think twice about the hardware sitting inside a data centre until the next refresh cycle rolls around. It’s one of those quiet, behind-the-scenes routines that keep operations moving, swap the old gear, slide in the new, and get back to business. But look a little closer, and the gap between “old” and “unusable” hardware is wider than we admit.
Take a standard compute cluster running a mix of virtualised workloads and light AI inference. In most facilities, that server is pulled out after three to five years, not because it’s faulty, but because newer generations push denser performance per watt.
Multiply that early retirement pattern across thousands of racks, and you’re looking at a hardware lifecycle that’s fast, expensive, and far more wasteful than the industry intended. That reality is now forcing operators to rethink how long hardware should live, and more importantly, how to keep it productive without sacrificing uptime or efficiency.
How the linear hardware model became the industry’s default
The way data centres manage hardware today still follows a straight, predictable line: buy new equipment, deploy it, run it for a few years, and then retire it long before it’s genuinely unusable.
Most operators do this almost on autopilot because refresh cycles are tied to performance gains, service-level expectations, and budget planning. In practice, servers are usually replaced every three to five years, not necessarily because they’ve failed, but because newer generations deliver better performance per watt or higher density.
Average Server Refresh Cycle (2015 vs 2025)
![]()
You see this reflected everywhere from operator conversations to industry forums, where a “3-5 year cycle” is treated as standard practice. It keeps infrastructure up to date, but it also means perfectly functional hardware exits the floor far earlier than its true lifespan.
Zoom out, and that early retirement pattern ties directly into a much bigger issue. The world generated 62 billion kilograms of e-waste in 2022, with only 22.3% formally collected and recycled in an environmentally sound manner, according to the Global E-Waste Monitor 2024.
Global E-Waste Generation Trend (2010 → 2022 → Projected 2030)
![]()
Valuable materials like gold, silver, copper, and rare earth elements often remain unrecovered, even though they could theoretically be extracted and fed back into manufacturing loops. Combine that with the supply-chain strain of constantly procuring new servers, and you get a lifecycle model that is increasingly expensive, increasingly wasteful, and increasingly out of sync with sustainability and ESG expectations.
It’s no surprise then that operators are starting to question whether the traditional refresh mindset still makes sense in an industry where uptime is critical, hardware demand is surging, and the value locked inside every retired server is too high to ignore.
How Smarter Hardware Extends Its Own Life
Data centres are quietly getting smarter, not just in how they compute, but in how they preserve and reuse their own hardware. One of the biggest game changers is modular server architecture. Instead of tossing out a server when one part becomes outdated or fails, modular design lets operators unplug and swap individual components.
According to Intel, this isn’t just about convenience; modular systems are made for reuse, repair, and lower waste. By decoupling server parts, you reduce complexity and make it easier to maintain or upgrade just what’s needed, rather than replacing whole units.
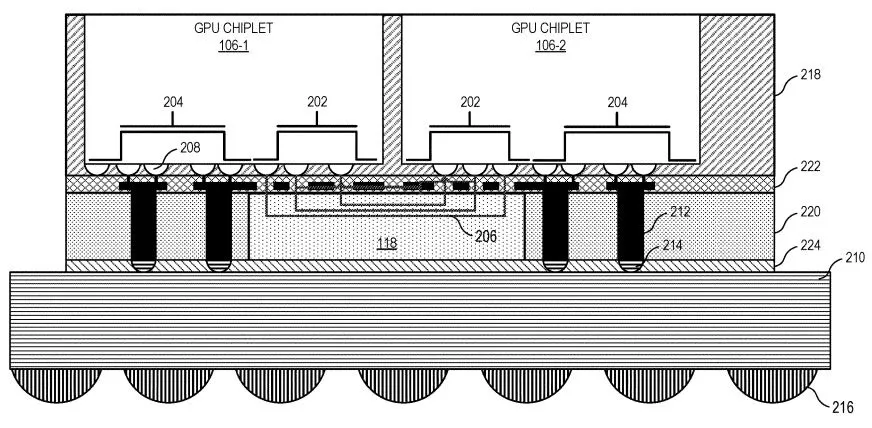
Then there’s the rise of chiplet-based CPUs and GPUs, which allow upgrades at a granular level. With chiplets, you don’t need to buy an entirely new processor; you can just replace or add certain building blocks.
This keeps performance growing without tossing out the full silicon die, helping stretch the useful life of high-value chips.
And this trend isn’t theoretical; chaplet-based server designs are steadily becoming mainstream, growing from single-digit adoption today to nearly half of all servers by 2030.
Percentage of Servers Using Chiplet Architectures (2023–2030)
![]()
Hardware is also getting more self-aware. Modern servers use real-time telemetry and health scoring to monitor component wear. This kind of continuous monitoring means potential issues are flagged long before they cause failures, so operators can intervene only when needed, keeping SLAs solid but avoiding unnecessary hardware retirement.
On top of that, big players are building remanufacturing pipelines: once a server reaches the end of its first life, it's sent back, safely wiped, disassembled, and rebuilt using certified parts. Google, for example, dismantles decommissioned machines, inspects the parts, and reuses them to build remanufactured servers that perform like new.
Finally, firmware is playing a critical behind-the-scenes role. Firmware-driven lifecycle control, using intelligent performance governors and in-band controllers, dynamically adjusts cooling, power, and performance. This reduces stress on components and slows down ageing, all without manual intervention.
Together, these innovations don’t just make hardware last longer; they let hardware play a more active role in managing its own lifecycle, aligning performance, reliability, and sustainability in one smart, circular package.
How Leading Vendors Are Rewriting Hardware Lifecycles
Vendors and hyperscalers are no longer treating retired servers as trash; they’re treating them as a second chance. Dell runs certified refurbishment and asset-recovery services that rebuild returned PowerEdge systems for resale, reducing waste and recovering value.
HPE pairs its GreenLake and asset-upcycling services with formal take-back and recycling reporting, positioning reuse as part of procurement and lifecycle contracts.
Hyperscalers have gone even further: Google documents long-running circular practices that include refurbishment, redistribution and reuse of components from decommissioned machines.
Microsoft now operates Circular Centers to harvest, test and redeploy parts internally and reports a >90% reuse/recycling rate in recent reporting. AWS operates reverse-logistics hubs that de-manufacture, repair and test retired racks and components for reuse in other sites.
OEMs such as Lenovo and Cisco offer certified remanufactured programs and asset-recovery solutions that plug directly into enterprise procurement, giving operators an on-ramp to buy certified second-life kit with warranties and support.
Commercially, these moves lower TCO, shorten lead-time risk for critical components, and improve carbon accounting by keeping valuable materials in circulation instead of sending them to be recycled or landfilled.
For operators, the practical takeaway is clear: partner with vendors that bake circularity into buying, resale, and support models rather than treating reuse as an afterthought.
Why Circularity Now Feels Inevitable?
Circular hardware isn’t a side initiative anymore. It’s becoming the default direction because it fits the operational reality of modern data centres. Servers are getting more modular, OEMs now run mature take-back and recovery programs, and hyperscalers are proving you can maintain uptime while extending hardware life.
This shift isn’t driven by sustainability alone; it’s driven by cost pressure, supply-chain volatility, and the need to avoid constant full-system refreshes.
In the next few years, the transition will show up quietly: in procurement language, extended warranties, and refresh schedules that rely on condition data rather than age. Telemetry-based health scoring will make upgrades smarter and far more selective. Certified refurbished gear will feel less like a compromise and more like a normal operational choice backed by SLAs.
For operators, the takeaway is straightforward: plan for circularity now. It reduces risk, stabilizes budgets, and keeps well-performing hardware in circulation longer.
A circular model isn’t about stretching old machines; it’s about maximizing the value of what already works. And that mindset is what will set the next generation of operators apart.