For decades, data centers scaled by adding more CPUs. Performance grew linearly, power density remained manageable, and rack design followed predictable curves.
That model has broken.
Modern GPUs now deliver orders-of-magnitude acceleration for parallel workloads. The NVIDIA H100 Tensor Core GPU, for example, delivers up to 4x higher AI training performance compared to its predecessor generation under specific workloads, while dramatically increasing throughput for large-scale inference. At the same time, total board power for high-end accelerators now exceeds 700 watts per unit, pushing rack densities beyond traditional enterprise thresholds.
This is not just about faster AI training. GPUs are reshaping high-performance computing, financial modeling, scientific simulation, and real-time analytics. Parallel processing has moved from niche to default for compute-intensive tasks.
The infrastructure implications are equally dramatic. A single AI training cluster can require tens of megawatts of power, advanced liquid cooling systems, and tightly optimized interconnect fabrics. Performance gains are undeniable, but so are the energy and design trade-offs.
GPU-powered infrastructure is not an incremental upgrade. It represents a shift from general-purpose compute to accelerated architecture, and efficiency now depends as much on system design as on silicon.
Acceleration Becomes the Default Compute Model
GPU acceleration is no longer confined to research labs or elite supercomputers. It now anchors mainstream cloud, enterprise AI, and high-performance computing environments.
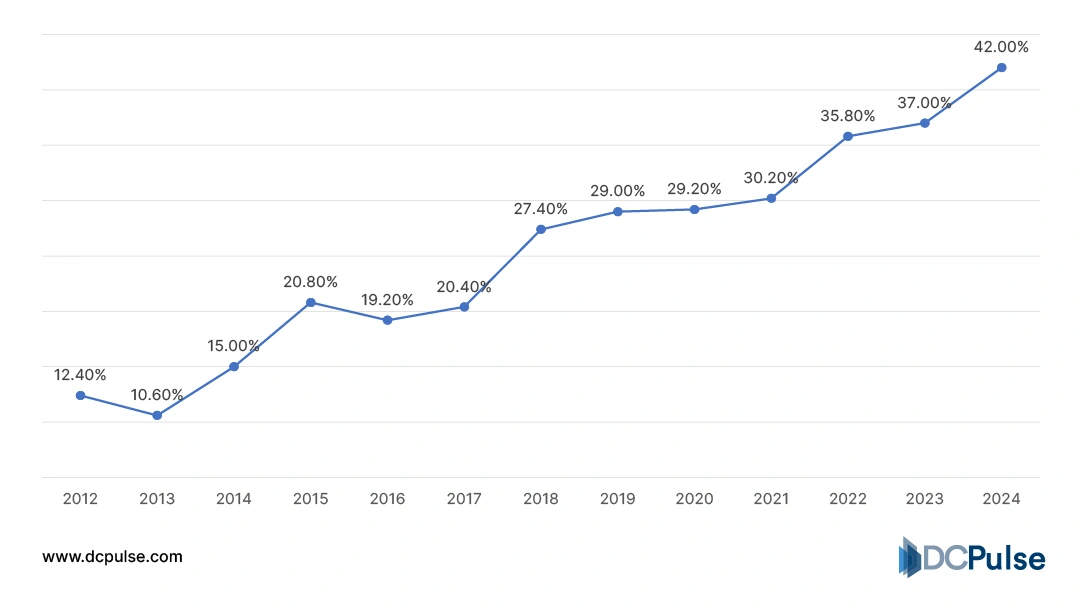
According to the TOP500, the majority of the world’s most powerful supercomputers now rely on accelerator-based architectures, with GPU-accelerated systems dominating the highest performance tiers. Systems such as Oak Ridge National Laboratory’s Frontier supercomputer combine CPUs and GPUs to achieve exascale performance levels exceeding one exaflop.
Accelerator Adoption in TOP500 Systems (2012-2024)
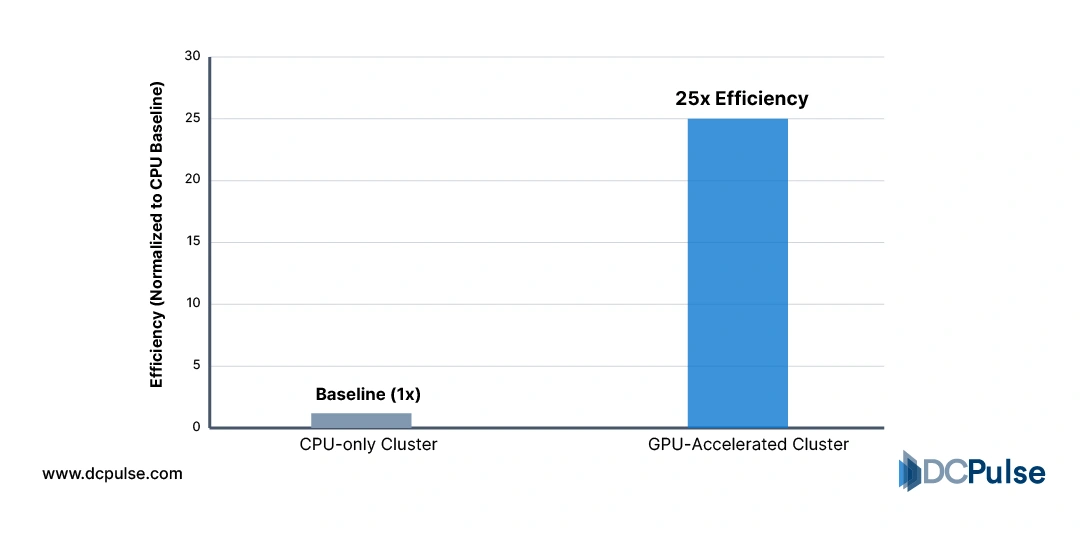
The efficiency argument is equally compelling. Parallel workloads, such as AI model training and scientific simulation, achieve significantly higher performance per watt on GPUs compared to traditional CPU-only clusters. NVIDIA reports that accelerated computing can deliver multiple times better energy efficiency for AI training relative to CPU-based approaches under comparable workloads.
Performance-Per-Watt - CPU vs. GPU for AI Training
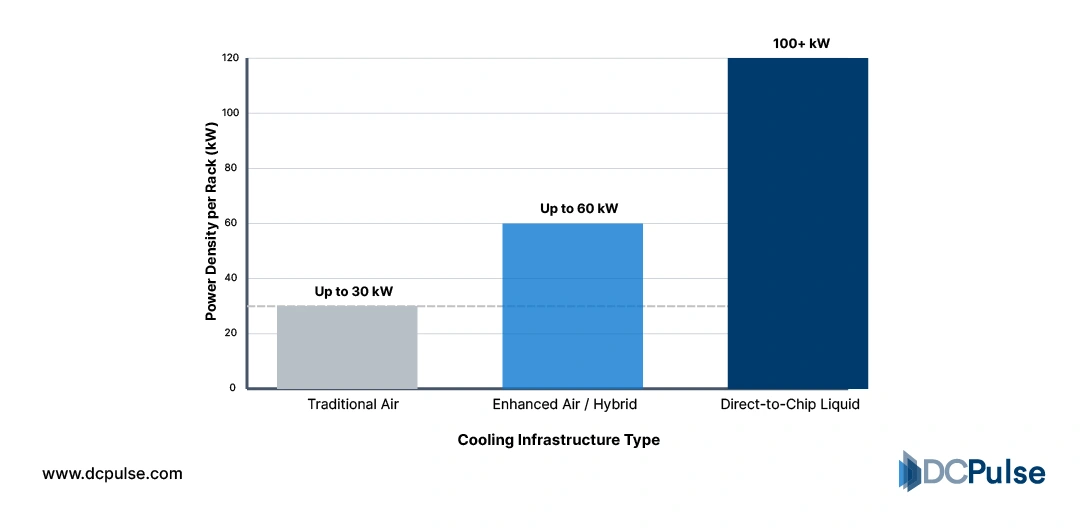
But the shift carries infrastructure consequences. Traditional enterprise racks averaged 5-10 kW. Modern AI racks can exceed 30-60 kW, and next-generation deployments are pushing beyond 100 kW per rack, driving adoption of liquid cooling and redesigned power distribution architectures.
Acceleration has become the default model for compute-intensive workloads. The challenge now is not performance capability; it is sustaining efficiency at scale without overwhelming the physical limits of the data center.
Engineering for Density: The Next Phase of GPU Infrastructure
As GPU deployments scale, innovation is shifting from raw silicon gains to system-level optimization. Performance increases are now tightly linked to memory bandwidth, packaging architecture, interconnect speed, and cooling design rather than compute cores alone.
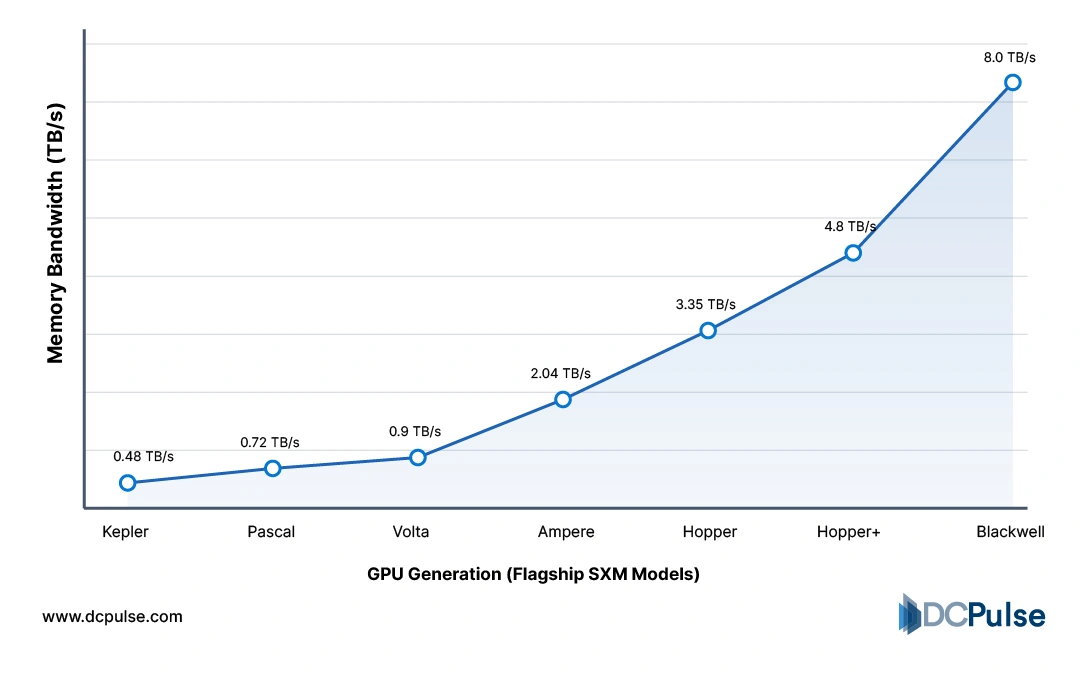
Modern accelerators rely on high-bandwidth memory (HBM) to feed massively parallel processing units. The NVIDIA H100 integrates HBM3 to significantly increase memory throughput over previous generations, enabling faster large-model training and inference. At the same time, advanced packaging techniques such as chiplet integration and 2.5D stacking reduce latency between compute dies and memory stacks. These packaging innovations are becoming as strategically important as transistor scaling itself.
Memory Bandwidth Growth Across GPU Generations
Architectural integration is also tightening. The NVIDIA Grace Hopper Superchip combines CPU and GPU into a unified module connected via high-speed coherent interconnect, reducing bottlenecks between general-purpose and accelerated workloads. This reflects a broader industry shift toward tightly coupled heterogeneous computing rather than discrete accelerator add-ons.
Interconnect design has become equally critical. NVLink and high-speed fabrics from vendors such as Broadcom allow GPUs to operate as unified clusters rather than isolated processors. As AI models scale into the hundreds of billions and trillions of parameters, east–west traffic inside racks rivals traditional north–south flows.
Cooling remains the physical constraint. The Uptime Institute highlights accelerating adoption of liquid cooling to support racks exceeding 80-100 kW in AI-focused deployments. Efficiency is no longer a chip metric; it is the outcome of tightly integrated compute, memory, networking, and thermal design.
Rack Density vs. Cooling Method Evolution
Strategic Capital and Supply Chain Realignments
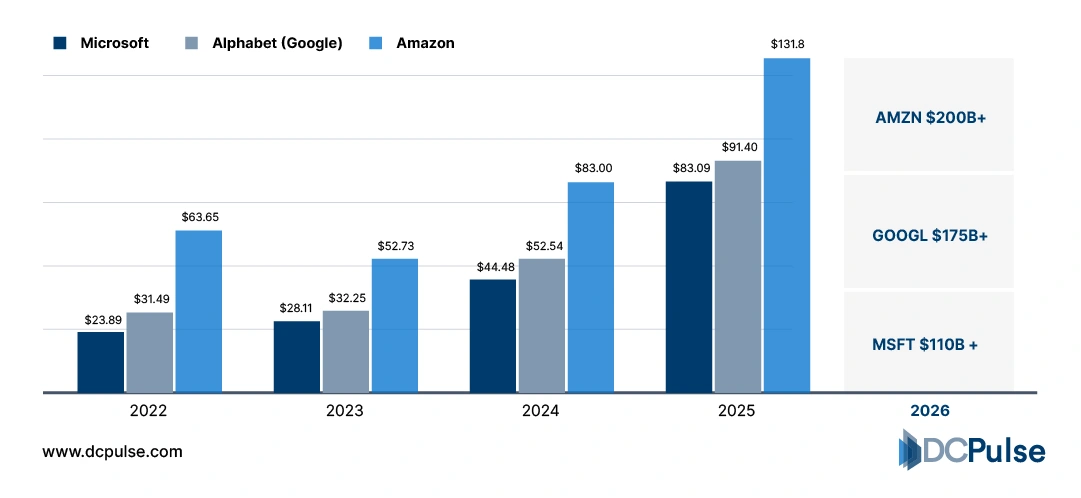
The race to deploy GPU-powered infrastructure is now shaping capital allocation across hyperscalers and hardware vendors. Companies including Microsoft, Amazon, and Google significantly increased capital expenditure to expand AI-optimized data center capacity, driven largely by accelerator demand.
Hyperscaler Capital Expenditure (2022–2025)
Supply constraints have also become strategic variables. Advanced packaging capacity and HBM production have tightened as AI workloads surge. Memory manufacturers such as SK hynix have reported strong HBM demand linked to AI accelerator deployments. This has shifted bargaining power upstream in the semiconductor value chain.
Meanwhile, infrastructure vendors are expanding liquid-cooled rack solutions and high-speed networking portfolios to support next-generation clusters. The system, not the standalone GPU, is now the competitive battlefield.
GPU infrastructure scaling is no longer purely a technical challenge; it is a supply chain, capital planning, and ecosystem coordination challenge.
Where Performance Meets Physics
GPU-powered infrastructure is redefining the economics of performance. The next phase will not be won by raw compute gains alone, but by how effectively operators balance density, efficiency, and supply chain resilience. As AI workloads scale, power availability and cooling architecture will increasingly determine deployment velocity as much as silicon roadmaps.
Industry forecasts reflect sustained acceleration. Gartner projects continued growth in AI infrastructure spending across enterprise and hyperscale environments. At the silicon layer, roadmaps from NVIDIA signal further integration and performance scaling in future data center platforms.
Strategically, three imperatives stand out: design for rack-level power densities beyond traditional thresholds; secure upstream access to memory and advanced packaging; and invest in liquid cooling and high-speed interconnect early. GPU infrastructure is no longer a performance upgrade; it is a structural redesign of the modern data center.
The organizations that align capital, architecture, and supply chain discipline will define the next decade of digital scale.