When the world decides to shop or stream, all at once, even giants on the internet can stumble. On 26 November 2025, as the world queued up to binge the latest season of Stranger Things, Netflix buckled under the surge, leaving thousands of viewers worldwide staring at buffering wheels and error messages instead of the episode premiere.
Just weeks earlier, on 20 October 2025, a massive outage at Amazon Web Services (AWS), the cloud backbone for thousands of e-commerce and digital platforms, took down dozens of major sites globally. Online stores slowed, checkout flows broke, and product pages failed to load or timed out.
Two different triggers, one a streaming release, the other a cloud-side failure. But the effect was the same; a sudden flood of demand exposed infrastructure weaknesses no one planned for.
This fragility isn’t just a streaming problem or a retail problem. It’s a challenge of scale and of architecture. These are the moments that separate platforms built for “average load” from those built to survive the surge.
The Surges Expose the Limits of Infrastructure
In a 24-hour span in November 2025, the ripples of digital overload stretched far beyond a single streaming platform. On 18 November, Cloudflare, the traffic-handling backbone for a huge portion of the modern internet, suffered a widespread outage triggered by a configuration-handling bug.
The disruption briefly knocked platforms like X (formerly Twitter), ChatGPT, and several streaming and commerce sites offline, a failure that highlighted how dependent the global web has become on a small set of distributed infrastructure providers.
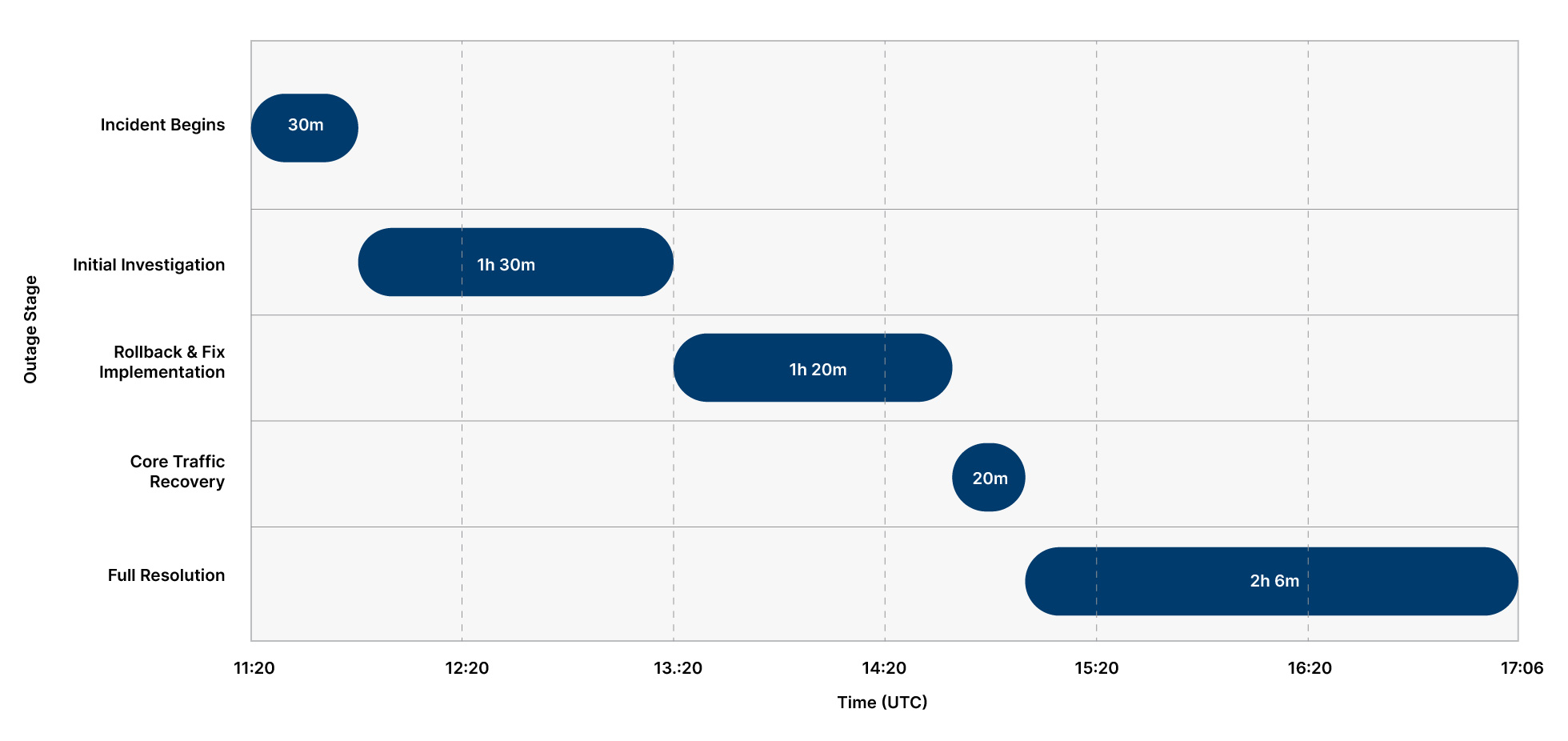
Cloudflare Outage Timeline Progression
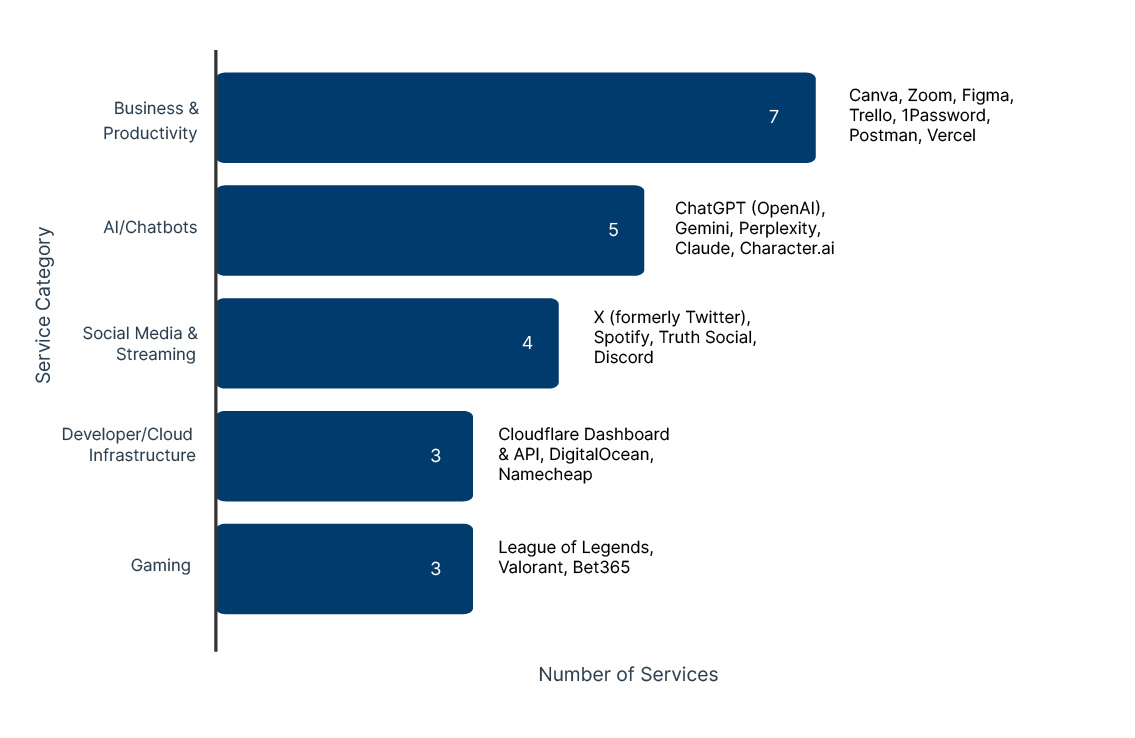
Count of Major Services Affected by Cloudflare Outage (Category and Affected Companies)
The retail world faced a parallel stress test. In the weeks leading up to Black Friday, multiple global e-commerce platforms reported severe slowdowns as millions of shoppers converged in narrow windows to secure limited-stock deals. Checkout flows stalled, inventory-reservation systems misfired, and payment gateways began timing out.
E-commerce Concurrent Request Surge: Peak Sale vs. Baseline
What looked like isolated glitches were symptoms of a deeper pattern: when concurrency spikes travel through every layer of the stack, CDN edges, cloud routing, application logic, session stores, and database writes, weaknesses compound rapidly.
Most failures during such events don’t originate in the user interface; they begin in the layers customers never see. A dependence on shared cloud and CDN services creates invisible single points of failure.
Stateful services like authentication or inventory locks collapse first because they must process every user action. And synchronous workflows, which rely on real-time responses, amplify even small latencies into full outages.
These breakdowns don’t arrive gradually. They strike in seconds, revealing which platforms are engineered for everyday traffic, and which are built for the surge.
The New Playbook for Handling Surges
To keep platforms steady when millions of users arrive at once, platforms are adopting a new generation of architectural patterns built around elasticity, proximity, and decoupling. One of the most important shifts is the rise of hyper-responsive autoscaling, where infrastructure expands in milliseconds rather than minutes.
Google Cloud has been sharpening this capability across services like Cloud Run, which can burst into thousands of containers almost instantly during traffic spikes, a design explicitly showcased in its latest performance.
This level of elasticity has become essential as concurrency curves steepen each year, a trend reflected in Shopify reporting a record USD 4.6 million in sales per minute during Black Friday-Cyber Monday 2024.
Traffic itself has become more unpredictable, and that’s pushing delivery closer to users. The move toward edge-heavy architectures accelerated after Akamai revealed that 88% of Disney+ launch traffic was served directly from its edge caches, a factor that kept the platform stable despite tens of millions joining on day one
Edge Offload Comparison: Edge Served Traffic Vs Origin Served Traffic

Another shift is architectural decoupling. Instead of tying critical functions to synchronous workflows that collapse under pressure, platforms are embracing event-driven pipelines, where asynchronous queues absorb bursts and release them gradually. This pattern has spread widely across commerce and ticketing platforms after multiple high-profile overloads in 2024-2025, documented in cloud reliability postmortems.
These innovations mark a clear turning point; resilience is no longer about defending servers; it’s about designing flows that stay smooth even when demand behaves wildly.
The Players Redefining Scale
The biggest platforms are no longer treating peak events as special cases; they are changing how they run the business. Amazon, Walmart, Shopify and Flipkart have invested heavily in operational playbooks that treat demand spikes as an expected mode of operation rather than an emergency.
Amazon’s recent holiday reports make it clear the company plans capacity and routing around recurring peaks, and Shopify’s public Black Friday, Cyber Monday data (merchants did a record USD 11.5 billion over the weekend, peaking at USD 4.6 million per minute) shows why merchant platforms must guarantee checkout continuity at massive scale.
Shopify Black Friday-Cyber Monday 2024: Peak vs Average Minute Sales
Flipkart and Walmart have taken a more platform-engineering route. Flipkart’s Big Billion Days now leans on cloud-native databases and tiered caching (Google Cloud has documented Flipkart’s use of Bigtable for large-scale events), while Walmart blends in heavy automation and AI to smooth inventory and fulfilment during peak windows.
On the OTT side, Netflix, Disney+ and Prime Video have likewise turned operations into a repeatable engineering exercise. Netflix’s Open Connect and region-failover work show why localising traffic and building quick failover meshes reduce blast radii when a cluster is saturated. Disney+ and Hotstar have repeatedly invested in edge delivery and capacity planning after several high-concurrency live sporting events proved the consequences of under-planning.
These moves share a pattern, distributed capacity, localised delivery, and operational rehearsals. In practice, that means capacity planning is now continuous, failover is automated, and postmortems turn into code changes, not just process notes.
Designing for the Surge: Lessons Across Streaming and Commerce
The infrastructure lessons from OTT streaming and flash-sale e-commerce are converging. Platforms that once faced unrelated challenges, high-concurrency video premieres versus mass shopping spikes, are discovering a shared set of principles for surviving the surge. The failures of late 2025 serve as reminders that peak traffic is no longer an occasional stress test; it’s the baseline for planning.
Edge compute, predictive autoscaling, and graceful degradation are emerging as the common toolkit. Netflix’s regional failover meshes, Disney+’s edge-heavy delivery, and Shopify’s burst-ready container orchestration illustrate how latency-sensitive workloads benefit from being physically and logically closer to the user.
Similarly, predictive demand systems and asynchronous queues allow e-commerce sites to smooth spikes without breaking the user experience, lesson OTT platforms are increasingly adopting for live event releases.
The bigger shift is conceptual; engineers are moving from “design for peak” to “design for unpredictability.” Surges no longer follow calendars; they erupt spontaneously, sometimes triggered by social trends, global releases, or sudden cloud-side faults.
Resilience is now a shared discipline, one that bridges streaming and shopping. Success will belong to the platforms that treat high concurrency not as an exception, but as an expected, manageable reality, where every layer, from edge to core, anticipates the unexpected and keeps the user experience seamless.