In 2025, more than four out of five enterprises claim to run multi-cloud or hybrid environments, representing a tacit admission that the cloud is no longer a destination, but a sprawling ecosystem. As terabytes turn into petabytes and AI pipelines demand larger than ever datasets, a quiet force begins to shape enterprise architectures: Data Gravity.
This invisible pull doesn’t just affect data, it drags entire applications, workflows, and strategic choices into a fixed orbit. Understanding why data gravity matters more than vendor lock-in today is no longer optional: it is the first step in building cloud infrastructures that sustain.
The Cloud Sprawl That No One Planned For
Today, cloud usage is nearly universal. According to recent industry data, roughly 94% of enterprises globally use some form of cloud service, and a striking 83% report operating multi-cloud strategies.
Enterprise Cloud Usage and Multi-Cloud Adoption
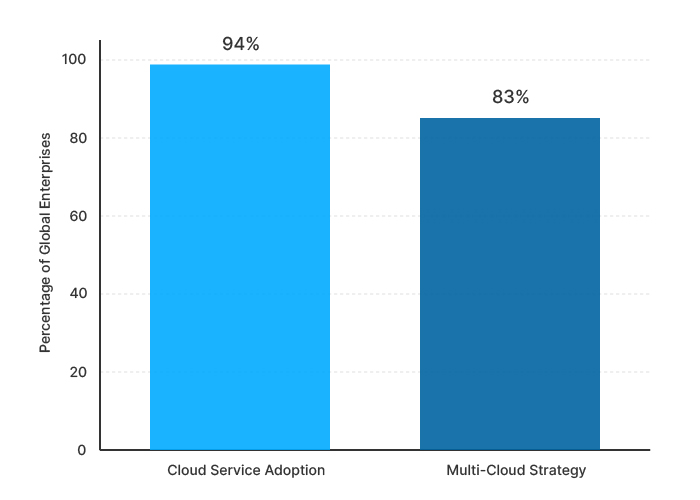
A survey finds that 84% of cloud-using organizations now deploy hybrid or multi-cloud environments, with only a small minority relying on a single public or private cloud.
Cloud Deployment Strategy of Global Organizations
What once began as a deliberate choice, a single public cloud, perhaps coupled with on-premises backbone, has quietly transformed into a sprawling and often unintentional multi-cloud reality. Mergers, acquisitions, regional compliance, and discrete team-level decisions have all contributed to it.
Today, enterprises don’t simply adopt “the cloud”; they inhabit a multiplex of clouds, public, private, on-premises, edge, often without a grand design.

This drift has a cost, the complexity. As workloads and data sprawl across providers and geographies, organizations struggle with governance, visibility, compliance, and latency. Inter-cloud cost, data transfer bottlenecks, and regulatory constraints make once-simple questions, “Where does this data live?” or “Which cloud runs this service?”, painfully, it’s hard to answer.
Enterprise Cloud Deployment Strategy Trend (2015-2025)
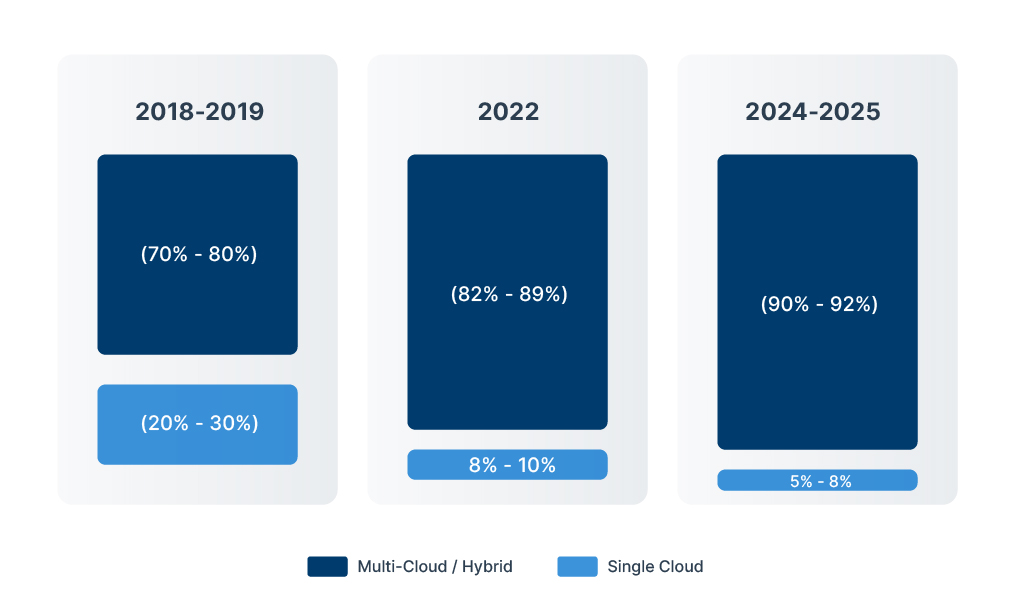
In short, what began as a cloud-first movement has spiked, often accidentally, into a cloud-everywhere entanglement. And this “sprawl” isn’t just organizational noise. As data volumes grow, it lays the foundation for a more fundamental challenge: the gravitational pull of data itself.
From Silos to Fabrics: Innovations Tackling Data Gravity
As enterprises shift from monolithic clouds to wide-spreading multi-cloud estates, a new tier of infrastructure is emerging, one that doesn’t just host workloads, but actively orchestrates, unifies, and optimizes data across on-prem, cloud, edge, and hybrid environments. These innovations, by Hammerspace, VAST Data, Equinix, NetApp, and others, are quietly reshaping what “multi-cloud” means in practice.
Hammerspace leads with a global namespace and a metadata-driven parallel file system that spans on-prem, cloud, and edge storage. With that, enterprises can “see” all their data as a single logical pool, no matter how physically distributed.
Its automated policy engine can then place, replicate or tier data transparently: data lives where it makes sense; applications access it as if local. For AI and high-performance workloads, Hammerspace offers “Tier-0” local NVMe acceleration to feed GPUs without network bottlenecks, enabling demanding workflows across hybrid-cloud setups.
VAST Data complements this with a scalable, hybrid-cloud–native data platform. As of 2024 it supports a global namespace extended to major public clouds (e.g. Google Cloud), making hybrid and native-cloud storage seamlessly integrated.
Through its collaboration with Equinix and its support for high-performance compute (e.g. NVIDIA DGX SuperPOD), VAST enables large-scale AI pipelines and data-intensive analytics without forcing data relocation.
On the interconnect side, Equinix, often working with NetApp, is building the “cloud-adjacent” backbone many enterprises now rely on. Their joint offering, combining Equinix Metal infrastructure with NetApp’s storage platforms, delivers low-latency bare-metal performance, full-stack storage/compute/networking, and tight integration with major public clouds, all under unified management.
This cloud-adjacent approach effectively collapses the distance (network and latency) between data storage and compute, circumventing many data-gravity obstacles.
NetApp itself continues to evolve its “data fabric” offering, embedding block, file, and object storage protocols into a unified storage stack usable across on-prem and cloud environments. With new all-flash systems engineered for AI-era workloads, enterprises can flexibly deploy or burst workloads across environments while keeping governance, performance, and storage efficiency intact.
Together, these innovations are shifting the paradigm: from cloud silos and fragmented data estates, to global data fabrics that treat data as a fluid, location-agnostic resource. For organizations wrestling with data gravity, storage sprawl, and multi-cloud complexity, these are the tools many are beginning to bank on.
The Deals Defining the New Multi-Cloud Reality
The market is moving from theory to execution, and it’s happening through partnerships and validated offerings that treat data as a managed, move-able asset rather than a set of isolated buckets. Recent deal activity makes that clear, VAST Data’s validated AI solution colocated inside Equinix IBX facilities (certified for NVIDIA DGX SuperPOD) is an explicit bet that customers want high-performance AI stacks placed next to their data and cloud on-ramps, not forced into long egress paths.
Equinix’s deeper product tie-ups with NetApp illustrate the same logic from the interconnect side: private storage connected through Equinix Cloud Exchange significantly improves throughput and lowers the effective distance between enterprise data and public-cloud compute. The message is simple, collapse network distance and policy friction, and the multi-cloud problem becomes manageable.
Google Distributed Cloud (GDC) and its Managed GDC partners are another strand of the story, sovereign and air-gapped GDC deployments (announced with regional partners and systems integrators) let governments and regulated firms run cloud-native services near their data while preserving full operational control, a clear response to data-sovereignty constraints that drive multi-cloud complexity.
Finally, some smaller but strategic moves, Hammerspace’s Tier-0 NVMe initiative and appliance partnerships (Arrow, Supermicro) plus its record MLPerf performance and rapid commercial growth, show how software-first data fabrics are being productized and integrated into vendor ecosystems. These deals and validations are reducing risk for enterprises that once feared the operational overhead of a true global data fabric.
Together these commercial plays do more than add products to a catalog; they rewire the economics and operational model of multi-cloud, making it possible to design where compute meets data instead of being forced into expensive, latency-bound lifts and shifts.
Designing for the Weight of Data
The next chapter of multi-cloud strategy is less about picking a single supplier and more about learning to place compute, governance and connectivity where data already lives. Enterprise datasets are growing at a scale that makes routine movement expensive or impractical, IDC’s Global DataSphere forecasts continued, steep growth in the world’s datasphere, a trend that underpins why so much data will soon be “too big to move.”
At the same time, cloud economics are shifting: Gartner forecasts robust public-cloud spending and predicts a near-universal shift to hybrid approaches, which together raise the stakes for tight integration between clouds and on-prem systems.
Architects should treat this as a placement problem, not simply a procurement one. The business reality is already visible in the market, multi-cloud adoption is widespread, Flexera’s 2024 State of the Cloud reports that roughly nine in ten organisations now operate multi-cloud strategies, which is why fabric and adjacency plays matter more than ever.
Commercial moves by infrastructure vendors prove the point, VAST Data’s validated AI offering colocated inside Equinix IBX sites (certified for NVIDIA DGX SuperPOD) and NetApp’s Storage on Equinix Metal partnership both reflect a clear industry bet, collapse network distance, keep data local when it matters, and expose a simple control plane for hybrid operations.
Concretely, this means mapping data by value and locality, investing in cloud-adjacent interconnects and bare-metal fabrics, and standardising a fabric or namespace so governance and policy travel with data. The organisations that succeed will be those that design around where data is heaviest, not around where compute is cheapest.