The moment an AI model leaves the benchmark and enters production, the problem changes completely.
In testing, a model answers prompts.
In production, it answers thousands simultaneously, continuously, and under strict latency guarantees. What mattered during training, accuracy and scale, are suddenly secondary to consistency, response time, and operating cost. A model that scores perfectly in evaluation can still fail in deployment if a single slow request stalls a transaction pipeline or a surge in queries overheats a GPU rack.
Inside a live data center, inference behaves less like research and more like industrial processing. Requests queue, memory fragments, and batch sizes fluctuate, and utilization oscillates between idle and saturated within seconds. The infrastructure doesn’t just run the AI; it shapes the AI’s behavior.
Production AI, therefore, is not a model problem.
It is a systems optimization problem, where compute placement, scheduling, and efficiency decide whether intelligence is usable or merely impressive.
From Benchmark Scores to Runtime Reality
A model in production does not experience queries one at a time.
It experiences them all at once.
Live services receive unpredictable request bursts, login spikes, payment peaks, and evening usage waves. Systems must answer instantly, not eventually. Because of that, operators design inference clusters around worst-case latency rather than maximum throughput. The result is a counterintuitive outcome: large portions of expensive accelerators sit idle most of the day so the system can survive a sudden surge without delay. Google’s distributed-systems research shows response time degrades dramatically once even a small fraction of requests wait in a queue, forcing systems to keep spare capacity available at all times.
Request Concurrency vs. Latency Metrics (2026 Benchmarks)
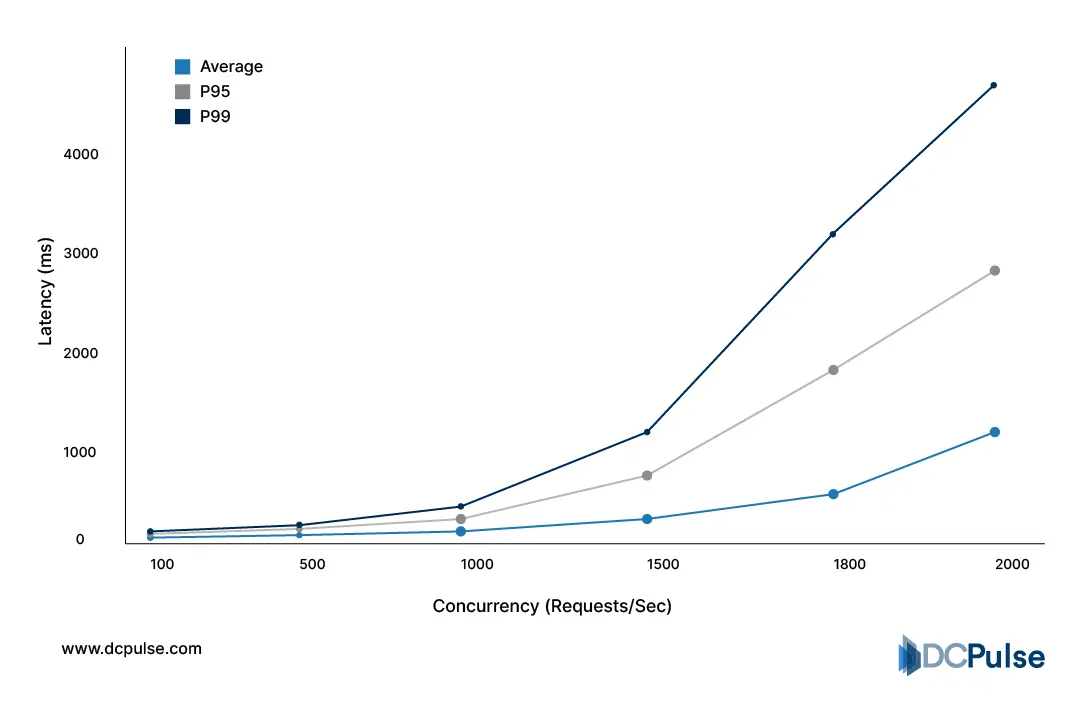
Memory creates the second bottleneck. Models must stay loaded in GPU memory to respond immediately, but real prompts vary in length. That variation breaks batching efficiency; some requests finish quickly while others occupy memory far longer, reducing overall throughput. NVIDIA’s inference performance guidance notes that sequence length variance directly reduces effective utilization in large-model serving environments.
Batch Efficiency vs. Token Length Variability (2026)
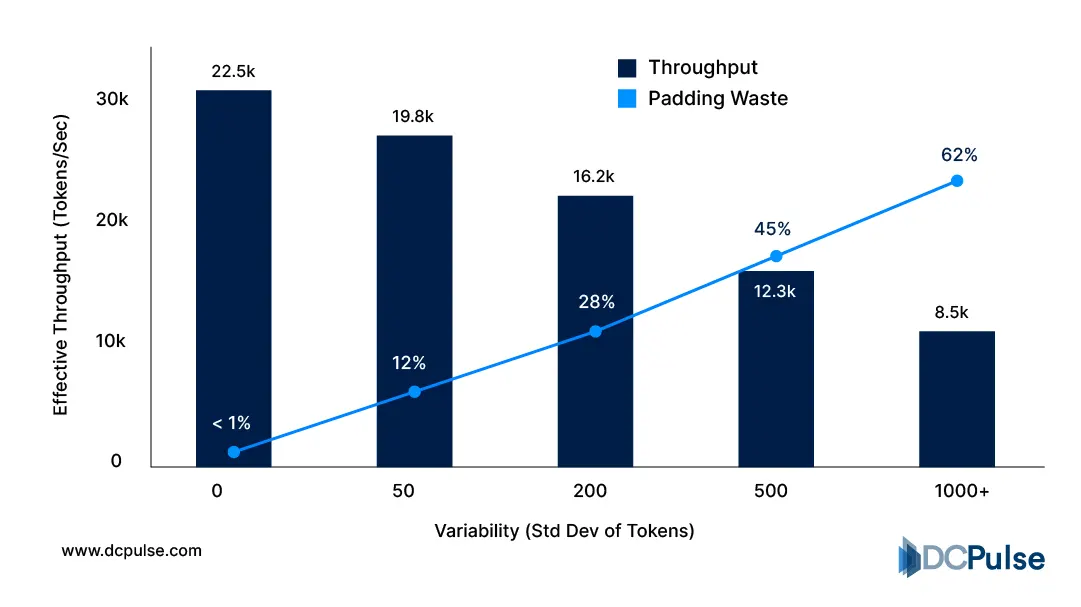
Because of this, production AI is continuously tuned rather than deployed once. Engineers adjust batching windows, routing rules, and cache behavior hour by hour to maintain latency targets, an operational pattern identical to overload management in large distributed systems.
Turning Models Into Systems
Once teams realized production AI behaves like a live service, optimization shifted from training tricks to runtime engineering.
The first change was compression. Instead of running full-precision models everywhere, operators increasingly reduce numerical precision to shrink memory footprint and increase parallelism. Lower-precision inference allows more requests to share the same accelerator while keeping latency stable, a technique widely adopted in large-scale serving because memory bandwidth, not compute, becomes the real bottleneck.
Throughput per GPU (Requests/Sec) by Precision - FP32 vs FP16 vs INT8 throughput per GPU
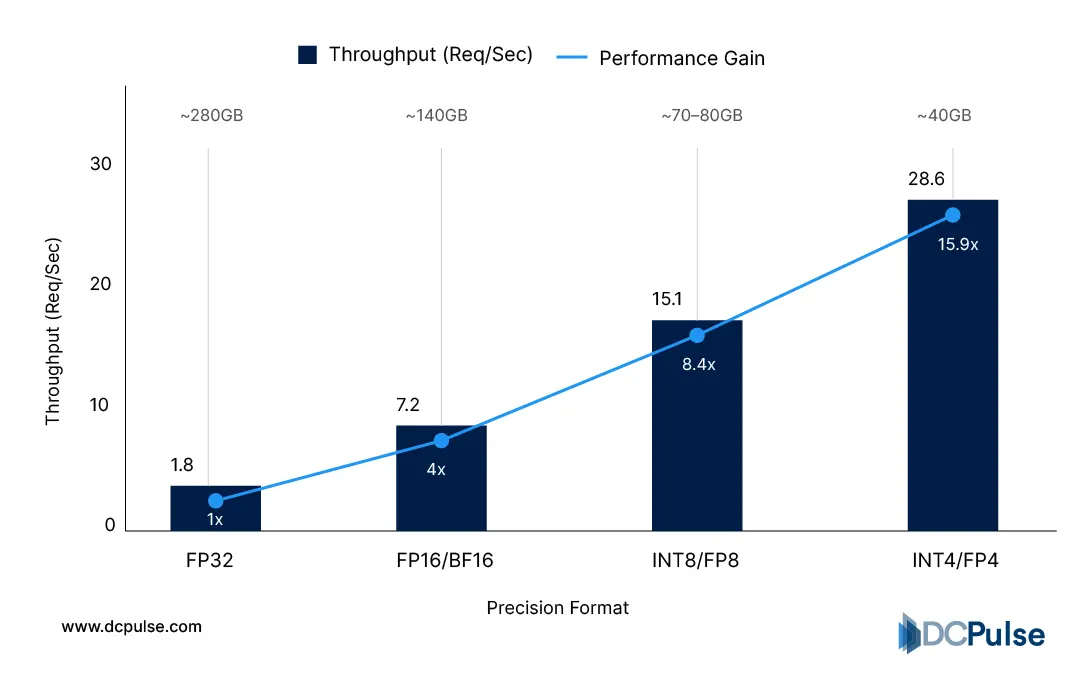
The second shift is dynamic batching and scheduling. Rather than processing requests immediately, systems hold queries briefly, for milliseconds, and group them to maximize hardware utilization without violating response targets. This converts random traffic into predictable compute workloads. Distributed serving research shows micro-batching significantly improves efficiency while maintaining tail latency constraints when carefully bound.
The third innovation is placement awareness. Not every request travels to the same compute location anymore. Short interactions run closer to users, while longer generations are routed to centralized accelerators. This hybrid routing reduces congestion and stabilizes performance by aligning workload duration with compute proximity, a pattern increasingly used in latency-sensitive online services.
How Companies Are Actually Fixing Production AI
As production constraints became clearer, major platforms stopped treating inference as a by-product of training and began designing software and hardware specifically for serving workloads.
Cloud providers introduced dedicated inference runtimes optimized for predictable latency rather than maximum compute density. These systems prioritize request scheduling, memory residency, and consistent response time over peak benchmark throughput, reflecting the shift from training clusters to always-on service infrastructure.
Chipmakers followed with hardware tuned for continuous inference. Instead of maximizing floating-point capability alone, newer accelerators focus on memory bandwidth efficiency and parallel request handling. The change acknowledges that production AI spends more time waiting on memory movement than performing math operations.
Software platforms are also separating model logic from execution logic. Serving frameworks now dynamically route requests based on queue depth and latency targets, turning AI deployment into a traffic management problem rather than a static workload. This approach mirrors large-scale service routing where stability matters more than raw performance.
The industry is no longer optimizing models alone.
It is optimizing the path every request takes through compute.
From Faster Models to Reliable Intelligence
The next phase of AI adoption will not be defined by larger models but by stable behavior under real demand. As organizations move critical workflows into AI-assisted decision systems, consistency becomes more valuable than peak capability. A slightly less powerful model that responds predictably will outperform a stronger model that fluctuates under load.
Production environments will therefore prioritize schedulability, memory stability, and response guarantees over raw throughput. Instead of scaling only with bigger accelerators, systems will scale through smarter execution, routing shorter tasks to nearby compute, reserving heavier processing for centralized clusters, and continuously adapting capacity before congestion appears.
In practice, AI will begin to resemble utility infrastructure. Users will not measure intelligence by benchmark scores but by whether it responds instantly every time. The competitive advantage will shift toward operators who can maintain performance during unpredictable demand, not those who only demonstrate technical capability.
The real breakthrough in applied AI will not be smarter answers.
It will be dependable answers.