
Walk into a modern AI data center and the first thing you notice isn’t the servers; it’s the constraints. Power budgets cap expansion before floor space does. Cooling lines are planned before hardware arrives. Network topology is discussed alongside model architecture.
The machine is no longer the center of design.
AI workloads don’t run on servers the way enterprise applications once did. They stretch across boards, across racks, and often across entire clusters, where performance depends less on processor speed and more on how quickly data can move and how consistently the system can dissipate heat.
That shift quietly changed the purpose of a server.
It is no longer a computer that lives in a data center.
It is a component of the data center itself.
Why Traditional Servers Break Under AI Workloads
Traditional servers were designed around an expectation: most applications wait on decisions, not math. A database query, a login request, or a web page render moves step-by-step through instructions. Faster cores reduce waiting time, so CPUs evolved to execute one thread extremely well.
AI workloads remove that waiting.
Instead of finishing one task before starting another, a model evaluates thousands of numbers at the same time. The Google TPU performance study describes neural networks as repeating the same operation across massive datasets, which favors wide parallel execution rather than fast sequential execution. Modern accelerator surveys make the same distinction; these systems chase sustained work completed per second, not how quickly a single task returns.
Execution Model - Single Instruction Stream vs Many Simultaneous Operations
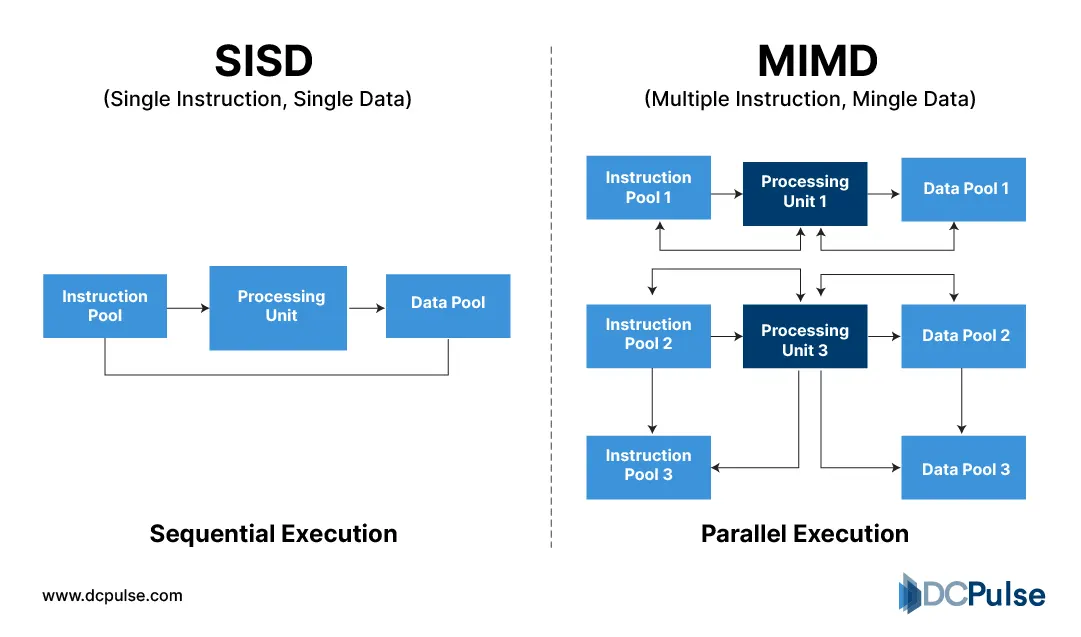
Once compute becomes parallel, processors stop being the slowest component. Moving data becomes the real work. The TPU analysis observed that arithmetic units often wait for weights and activations to arrive, a pattern also reflected in MLPerf inference measurements where performance scales only when memory delivery keeps pace.
Compute vs. Memory Performance Data Table
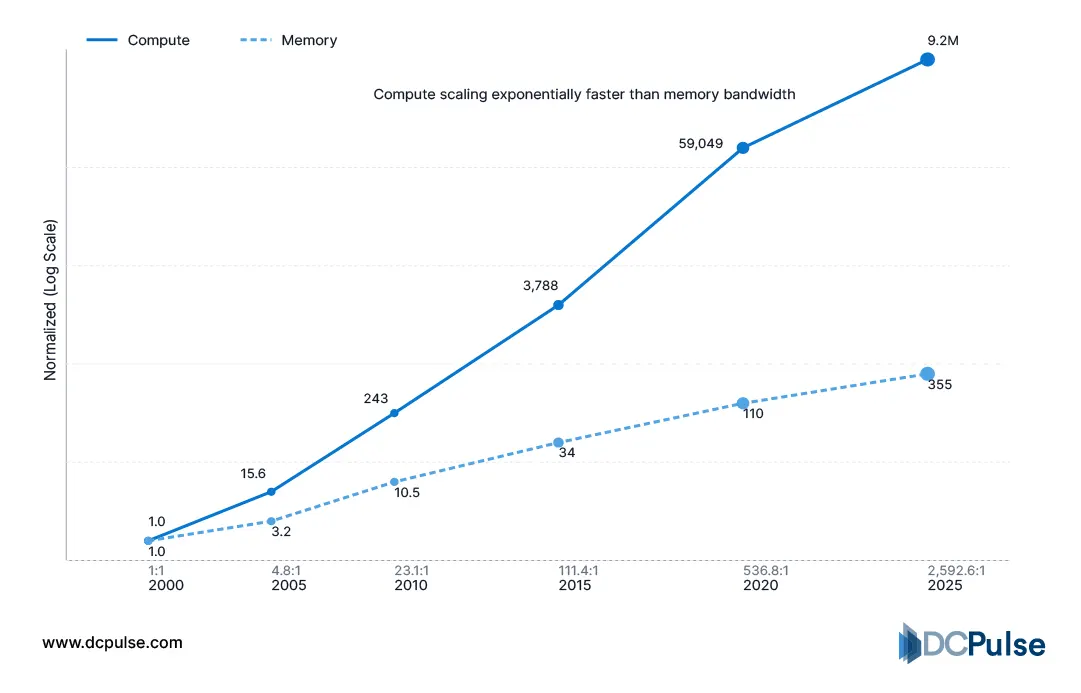
The problem grows beyond one machine. Large-scale training studies show performance increasingly depends on how efficiently machines exchange updates rather than how fast any individual processor runs. Techniques like ring-all exist purely to reduce communication overhead between nodes.
At the facility level, behavior changes again. Energy-characterization research shows machine-learning workloads run for long continuous intervals, creating steady utilization instead of the short bursts typical of enterprise traffic.
Traditional servers minimize response time.
AI systems must keep data moving without interruption.
What Does an AI-Native Server Actually Look Like?
AI infrastructure changes the job of a server from executing requests to sustaining work. Instead of waiting for bursts of activity, modern accelerator platforms are designed to operate continuously at high utilization, which is why industry benchmarks evaluate training systems by how consistently they maintain throughput across an entire run rather than peak performance.
To maintain that steady output, compute devices inside the same node communicate constantly. Open hardware designs now organize accelerators as a coordinated processing group rather than peripheral devices attached to a CPU, reflecting that large models execute across multiple processors simultaneously.
Vendor accelerator platforms similarly describe the processor complex as the primary compute element of the system rather than an attached component.
Compute vs. Tensor Exchange Time
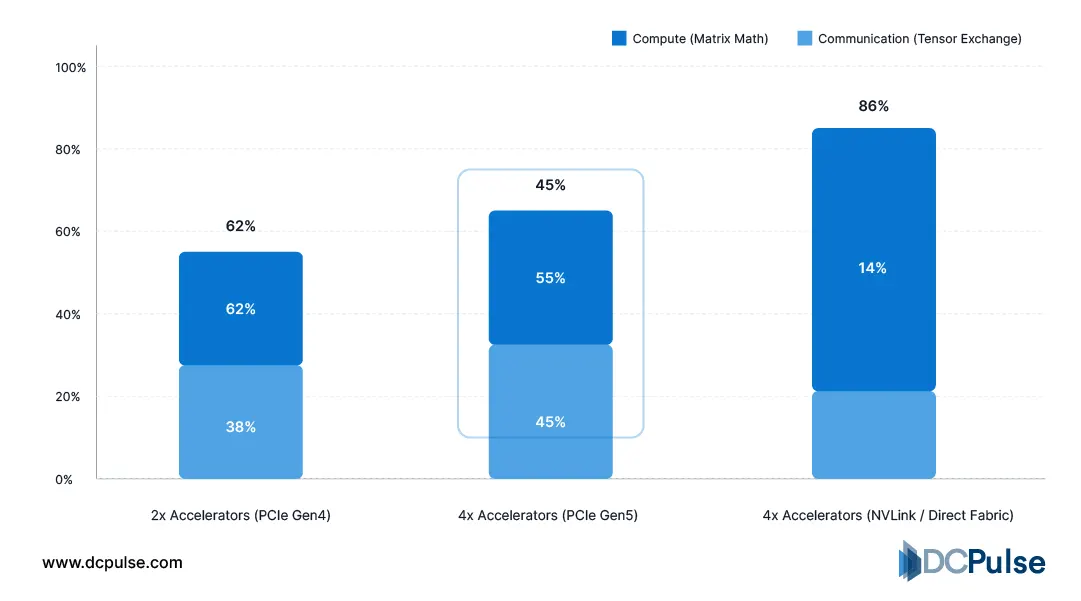
Continuous operation also reshapes thermal engineering. Data-center operators studying AI deployments report sustained high utilization compared with conventional enterprise workloads, which drives the need for cooling approaches engineered directly around the hardware instead of relying solely on room airflow. High-density accelerator systems are therefore designed so heat removal remains stable even as compute density increases.
Cooling Efficiency vs. Rack Density
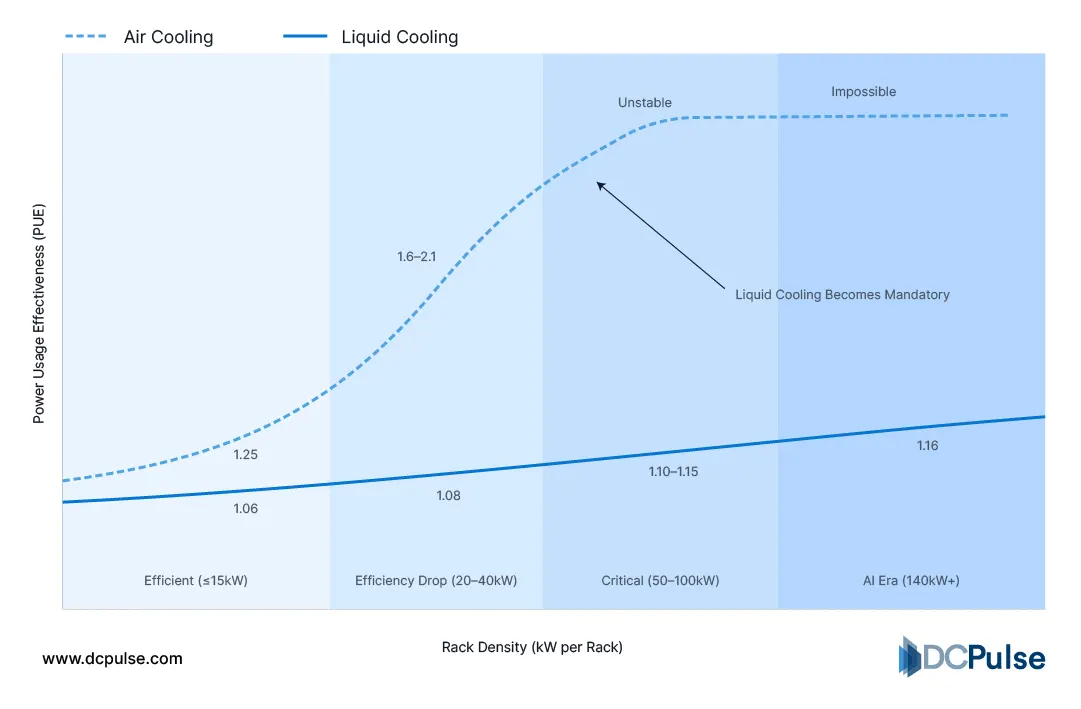
An AI-native server is not defined by a single processor.
It is defined by how reliably the entire node sustains coordinated computation without interruption.
Who Is Re-Architecting the Modern AI Machine?
AI infrastructure is changing how operators buy capacity, not just how they run it.
Instead of purchasing individual servers and integrating them over time, operators now deploy compute in predefined clusters. Large training environments are expanded by adding identical blocks of nodes so performance scales predictably, which is why benchmarking bodies evaluate repeatable multi-node scaling rather than single-machine speed. In practice, capacity planning shifts from counting servers to planning increments of total training throughput.
Hardware vendors have adapted their products to match this behavior. Modern accelerator platforms are delivered as complete systems, with processor, memory, and interconnect packaged together, allowing operators to deploy standardized compute units without tuning each configuration. This shortens deployment time because integration work moves from the data center to the manufacturer.
Facility design follows the same pattern. Operators now expect sustained utilization rather than variable enterprise demand, so halls are planned around predictable density bands instead of mixed workloads. Industry analysis notes AI environments maintain consistently high load, making power and cooling capacity a provisioning decision made before the first rack is installed.
The industry is no longer scaling infrastructure one machine at a time.
It is scaling repeatable compute units as operational building blocks.
Will the Server Disappear Into the Data Center Itself?
AI workloads are not just another application category. They redefine what efficiency means inside a data center.
For years, infrastructure optimization focused on utilization, keeping servers busy as often as possible. AI reverses the problem. Systems now run continuously by design, so the challenge becomes sustaining predictable operation instead of chasing higher peak usage. The success of a deployment depends less on individual component performance and more on how reliably the entire stack, compute, network, and cooling, behaves as a coordinated system.
This shift changes planning timelines. Capacity decisions move earlier in the project because density and power requirements are determined before installation, not discovered during operation. Hardware refresh cycles also become more structured, as expanding capability means adding matched compute groups rather than replacing scattered machines.
The long-term implication is simple: data centers stop behaving like shared environments and begin behaving like purpose-built production facilities.
Organizations that adapt their procurement, facility design, and scaling strategy to this model will treat AI infrastructure as a predictable industrial system rather than an experimental workload.




