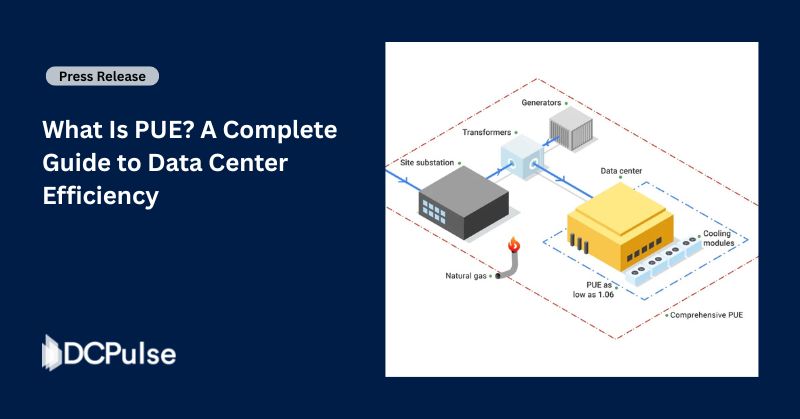
For years, automation in infrastructure meant speed.
Scripts executed faster than people, orchestration coordinated more systems at once, and large environments became manageable because repetitive work could run without manual effort.
But the responsibility never really moved.
When something failed, a notification still reached an operator. The system described the problem; a person decided the response. Automation handled execution, not judgment.
At scale, that boundary started to break.
Modern platforms generate more signals than teams can realistically evaluate, and waiting for human confirmation often takes longer than recovery itself. The question stopped being how to automate actions and became whether the system could choose the action.
Some failures now trigger remediation automatically.
Capacity shifts, services restart, traffic reroutes, and unhealthy nodes are removed without escalation. The change is subtle; the workflow no longer pauses for approval.
Automation used to follow instructions.
Increasingly, it interprets conditions.
Infrastructure is moving from performing tasks to handling outcomes, where recovery is designed into behavior rather than performed as an intervention.
Automation Still Waits for Permission
Modern infrastructure already runs on automation, but its authority is limited.
Provisioning, configuration rollout, and workload placement now happen automatically across most large environments. Platforms continuously enforce the declared state, replacing failed instances and maintaining availability. Kubernetes, for example, automatically restarts failed containers and removes unhealthy instances from traffic using health probes.
Yet the operational decision still sits outside the system.
Monitoring platforms detect abnormal behavior and escalate it rather than resolve it. Google’s Site Reliability Engineering guidance describes incident response as an on-call process where engineers evaluate alerts and coordinate mitigation. Automation executes recovery steps, but humans choose which recovery is appropriate.
Semi-Automated Incident Response Loop
This separation exists because automation operates on predefined conditions. It can enforce known corrective actions, but it cannot interpret ambiguous system behavior. At scale, that limitation becomes visible: distributed systems generate more signals than operators can meaningfully evaluate, and many incidents resolve through repetitive corrective actions rather than investigation. Studies of production cloud operations show high alert volumes requiring human interpretation despite automated detection.
Operators therefore encode boundaries instead of decisions. Systems restart services, reschedule workloads, and replace failed nodes automatically, but only inside predefined rules. When context matters, whether to drain capacity, reroute traffic, or alter workload behavior, the workflow still pauses for judgment.
The industry sits in a transitional phase.
Infrastructure can execute recovery instantly, but it still waits for permission to decide.
When Automation Starts Fixing Itself
Modern infrastructure automation is no longer just about provisioning faster; it is beginning to diagnose, decide, and repair without human escalation. The shift is being driven by three converging developments: event intelligence, intent-based control planes, and closed-loop remediation.
The first change is the replacement of static alerting with contextual event understanding. Observability platforms now correlate millions of signals across metrics, logs, traces, and topology graphs to determine causality rather than symptom noise. Instead of paging engineers for threshold breaches, systems identify the failure chain (overloaded queue → cascading retries → API saturation) and suppress secondary alerts. According to Dynatrace’s Davis AI architecture documentation, modern AIOps engines build dependency maps in real time and perform root-cause detection automatically, reducing alert volumes and accelerating remediation decisions.
The second shift is intent-driven infrastructure. Rather than scripting “how” to fix something, operators define the desired service state, latency SLO, replication factor, or workload placement boundary, and the control plane continuously enforces it. Platforms like Google Cloud’s Autopilot mode in Kubernetes and policy engines such as HashiCorp Sentinel translate policy into continuous reconciliation.
The system monitors drift and restores compliance automatically, meaning configuration errors correct themselves the moment they appear rather than during a maintenance window.
The third and most transformative development is closed-loop remediation. Here, automation doesn’t stop at detection; it executes corrective action and verifies recovery before closing the incident.
IBM’s operational AI guidance shows production environments now routinely perform actions such as restarting unhealthy containers, shifting traffic away from degraded nodes, regenerating failed pods, or triggering autoscaling policies, all without human approval when confidence thresholds are met.
Together, these capabilities create what operators call self-healing infrastructure. Failures become transient states rather than outages. The operational model shifts from responding to incidents to supervising policy behavior; engineers review decisions instead of executing them.
When Automation Became an Operational Weapon
The shift from automation as a tooling layer to automation as a competitive differentiator did not happen quietly; it happened through platform moves. Hyperscalers began embedding resilience directly into infrastructure control planes, and colocation providers quickly realized customers now expected the same behavior from physical facilities.
The turning point came when Google published reliability practices around site reliability engineering and error budgets. Operators stopped measuring uptime as a static SLA and started measuring recovery velocity instead.
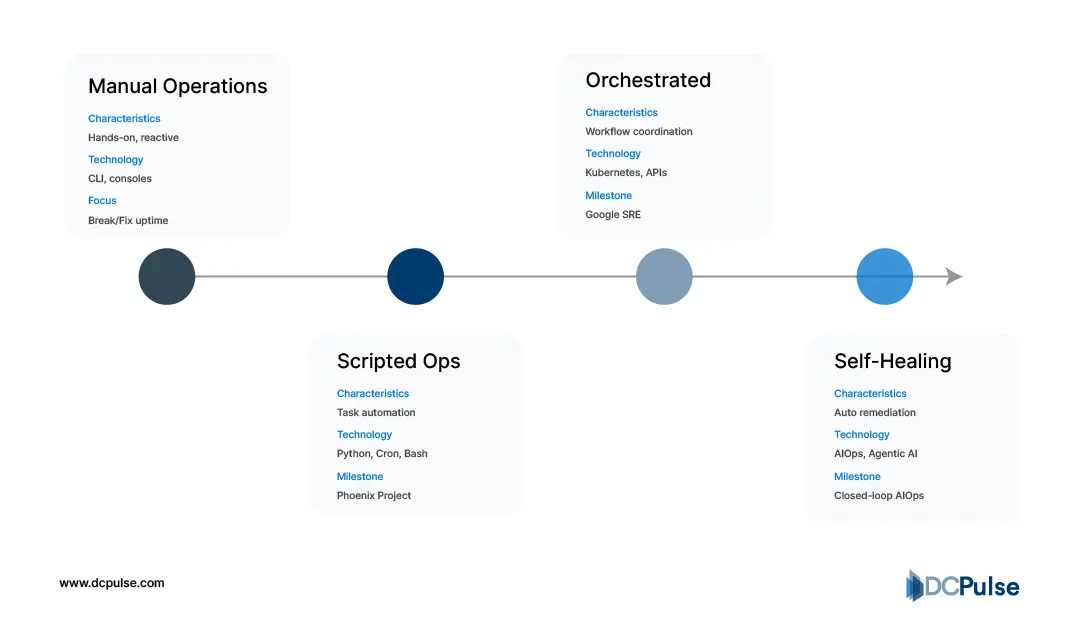
Evolution of Intelligence Maturity
Soon after, Microsoft integrated automated remediation workflows into Azure infrastructure, while Amazon Web Services expanded auto-recovery and health-based instance replacement. These weren’t cloud-only ideas; they reset customer expectations everywhere. A tenant colocating a rack now expects a failed power module to trigger the same automatic recovery logic as a failed VM.
Enterprise vendors followed. VMware embedded predictive maintenance and automated workload migration into its stack, and IBM pushed AIOps platforms capable of detecting infrastructure anomalies before alarms fired.
What changed colocation most was orchestration extending beyond compute. Facilities began wiring DCIM telemetry into orchestration engines so cooling failures, breaker trips, and thermal drift triggered the same workflows as software faults.
At that point, automation stopped being IT automation. It became facility behavior.
What This Means for Data Center Strategy
The real impact of automation at scale is not operational efficiency; it is operational predictability.
For decades, data center reliability depended on layered redundancy: dual power feeds, backup generators, redundant cooling loops, and standby hardware. Automation changes the reliability model entirely. Instead of surviving failures, facilities are beginning to avoid them.
Hyperscale operators already run availability engineering models where infrastructure is treated probabilistically rather than deterministically. Failure is assumed. The goal is containment.
Self-healing orchestration turns the data center into a continuously stabilizing system. When latency rises, workloads migrate. When thermal density shifts, cooling rebalances. When firmware faults appear, nodes are drained and replaced before service impact.
This shifts operational strategy from reactive maintenance to predictive behavior.
Capacity planning changes as well. Facilities no longer provision only for peak load; they provision for recovery bandwidth. Spare capacity becomes part of resiliency architecture rather than idle overhead.
The economic effect is significant. Instead of overbuilding infrastructure for safety margins, operators invest in intelligence layers that dynamically manage risk.
Over time, this redefines what uptime means.
Traditional uptime meant preventing downtime.
Autonomous uptime means maintaining service continuity regardless of hardware state.
The long-term consequence is architectural. The “data center” stops behaving like a building full of equipment and starts behaving like a distributed system that happens to occupy a building.
The facility itself becomes software-defined infrastructure.
And once infrastructure becomes software-defined, scale stops being a capacity problem; it becomes a coordination problem.
That is the endpoint of automation at scale:
not fewer operators, but fewer emergencies.