The rise of artificial intelligence is not just increasing demand for compute; it is changing how that compute is consumed.
Instead of owning and managing expensive GPU infrastructure, enterprises are increasingly turning to GPU-as-a-Service (GPUaaS), accessing high-performance compute on demand through cloud platforms. This shift is lowering the barrier to entry for AI development, enabling startups and enterprises alike to scale workloads without heavy upfront investment.
But this convenience comes with a structural impact.
GPUaaS is concentrating demand into large-scale data centers, particularly those equipped with high-density GPU clusters. These environments require significantly more power, cooling, and specialized infrastructure compared to traditional workloads.
At the same time, usage patterns are becoming more dynamic. Compute demand is no longer static; it spikes based on training cycles, inference workloads, and real-time AI applications.
The result is a fundamental shift:
Data center demand is no longer driven solely by storage or general-purpose compute but increasingly by high-intensity, on-demand GPU workloads, reshaping how infrastructure is designed, scaled, and deployed.
What Does the Current Landscape of GPU-as-a-Service Look Like?
The current GPU-as-a-Service (GPUaaS) landscape is defined by explosive demand for AI compute and rapid scaling of data center GPU infrastructure.
At the core of this shift is unprecedented growth in GPU demand. NVIDIA, the dominant supplier of AI GPUs, reported USD 47.5 billion in full-year data center revenue in fiscal 2024, with quarterly data center revenue reaching USD 18.4 billion, up over 400% year-over-year.
NVIDIA Data Center Revenue Growth (USD Billion)
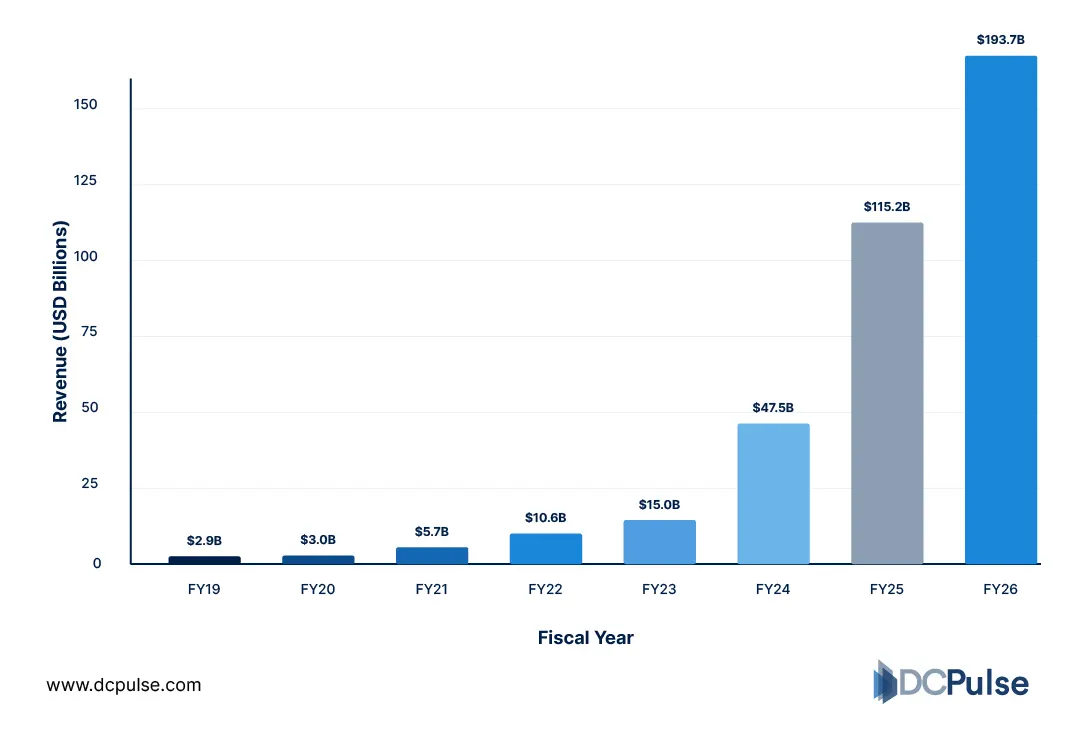
This surge is directly tied to AI workloads. Company disclosures highlight that demand is being driven by training and inference for large language models, cloud platforms, and enterprise AI adoption, indicating that GPU consumption is increasingly centralized in large-scale infrastructure.
At the infrastructure level, hyperscale platforms are expanding GPU access through service-based models. Cloud providers are deploying large GPU clusters and offering them on-demand, enabling enterprises to access high-performance compute without owning hardware.
Growth in Cloud-Based GPU Deployments
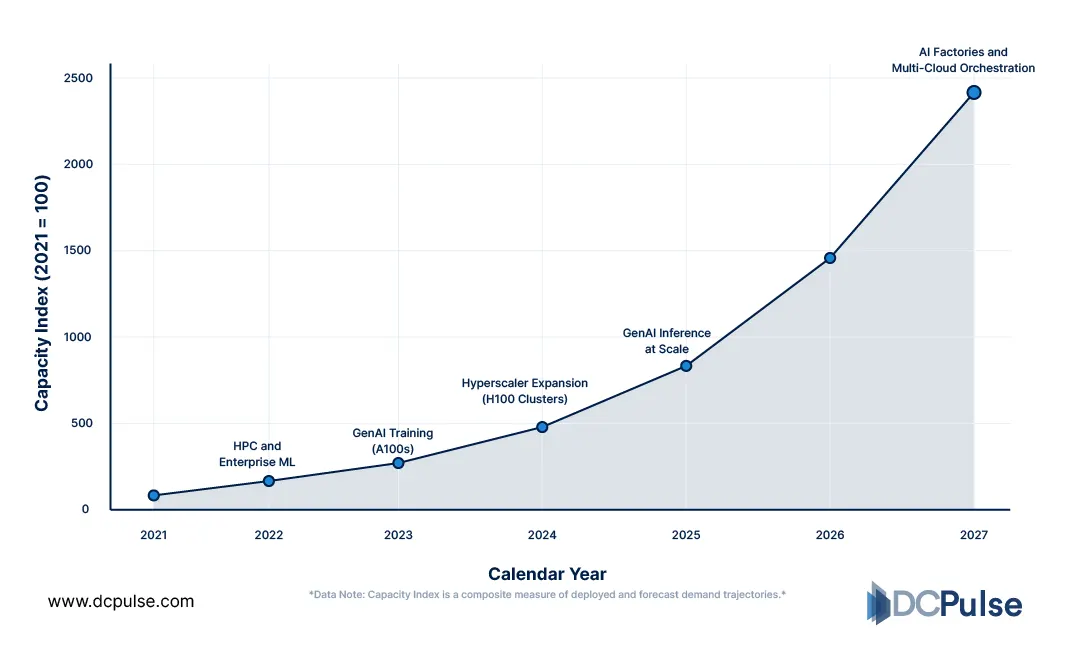
This shift is also changing demand patterns. Instead of predictable, fixed-capacity usage, GPU workloads are becoming bursty and highly variable, driven by training cycles, inference scaling, and real-time AI applications.
Shift from Static to Dynamic GPU Demand Patterns
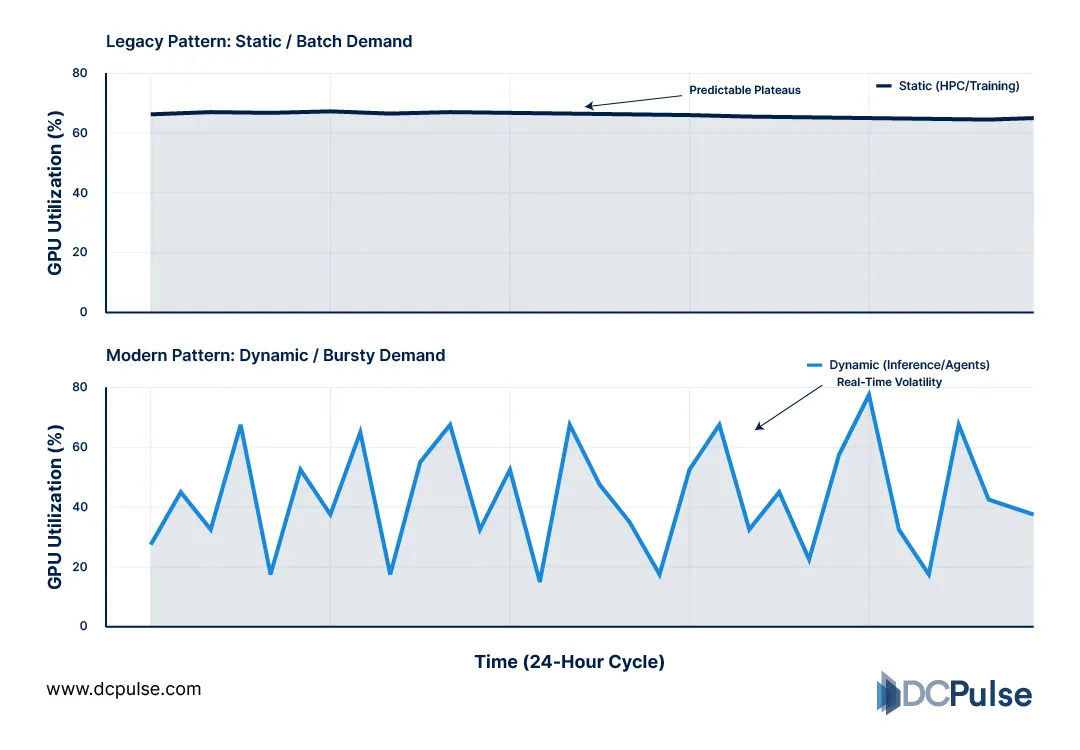
The pattern is clear;
The current landscape is defined by a centralized, service-driven GPU economy, where hyperscale data centers aggregate massive GPU capacity and deliver it on demand, dramatically increasing both the scale and volatility of data center demand.
What Innovations Are Enabling GPU-as-a-Service at Scale?
The rapid growth of GPU-as-a-Service is being enabled by innovations in GPU virtualization, resource partitioning, and multi-tenant infrastructure design, allowing providers to deliver high-performance compute efficiently at scale.
One of the most critical breakthroughs is hardware-level GPU partitioning. Technologies like Multi-Instance GPU (MIG), developed by NVIDIA, allow a single physical GPU to be divided into multiple isolated instances, each with its own compute cores, memory, and bandwidth. This enables up to seven independent workloads to run simultaneously on a single GPU, significantly improving utilization.
This innovation directly supports multi-tenant environments. Each instance operates with hardware-level isolation and guaranteed performance, ensuring that workloads do not interfere with one another, an essential requirement for cloud-based GPU services.
Parallel Workload Execution Performance (NVIDIA A100 MIG)
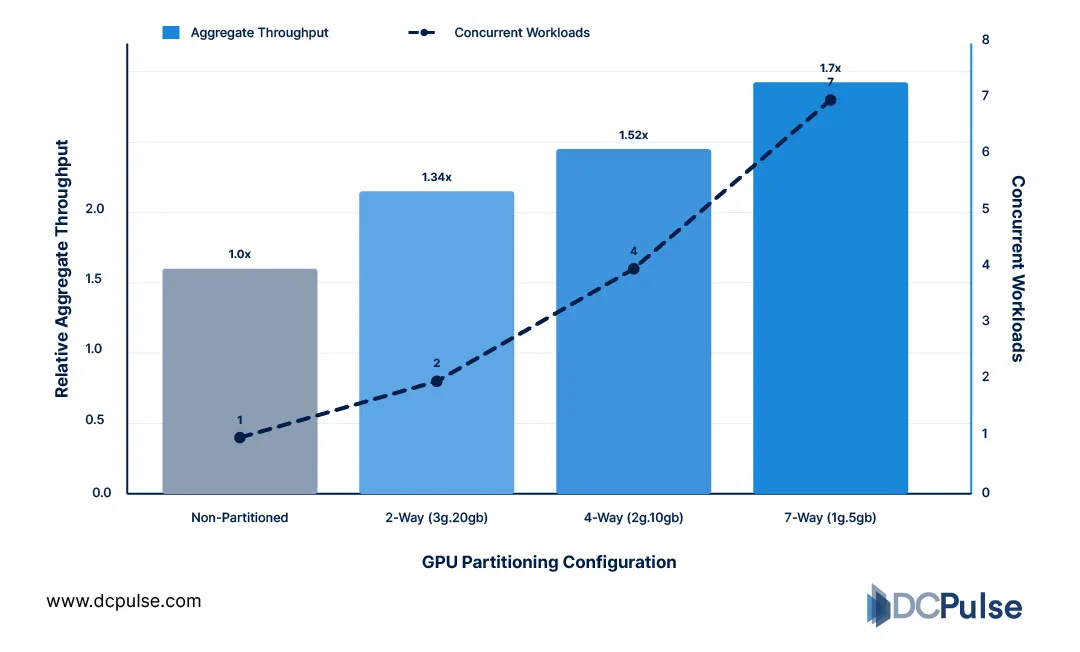
Another key enabler is GPU virtualization, where these partitioned instances are exposed to virtual machines as independent GPUs. This allows multiple users to access GPU resources concurrently while maintaining predictable performance and security.
These capabilities are further enhanced by integration with modern infrastructure tools such as containers and orchestration platforms, enabling dynamic allocation and scaling of GPU resources based on demand.
The shift is clear; GPU-as-a-Service is made possible by fine-grained control over GPU resources, transforming GPUs from single-tenant hardware into flexible, shareable, and scalable infrastructure components within modern data centers.
Who Is Driving GPU-as-a-Service Adoption Globally?
The adoption of GPU-as-a-Service is being driven by a multi-layered ecosystem of hyperscale cloud providers, specialized GPU cloud companies, and hardware suppliers, all responding to surging AI demand.
At the platform level, hyperscalers such as Amazon Web Services, Microsoft, and Google dominate the market by offering scalable, on-demand GPU infrastructure integrated with AI and cloud platforms. Industry analysis shows these players are leading due to their ability to combine global infrastructure, enterprise trust, and tight integration with AI ecosystems.
Market Share of Leading Hyperscale Providers (Q4 2025 - 2026)
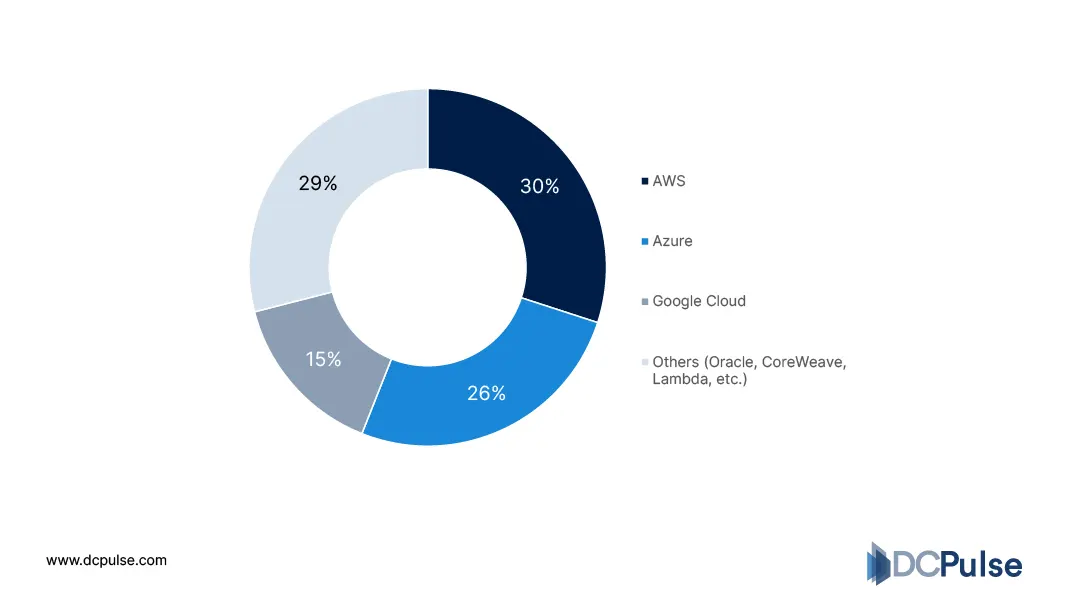
At the same time, specialized GPU cloud providers are emerging to address gaps in supply and flexibility. According to S&P Global, these providers are expanding rapidly to meet demand that hyperscalers alone cannot fully satisfy, offering purpose-built GPU infrastructure and more flexible configurations for AI workloads.
Underlying both layers is accelerating market demand. The GPU-as-a-Service market is projected to reach over USD 14 billion by 2033, driven by widespread adoption of AI and machine learning across industries.
GPUaaS Market Growth Forecast (USD Billion)
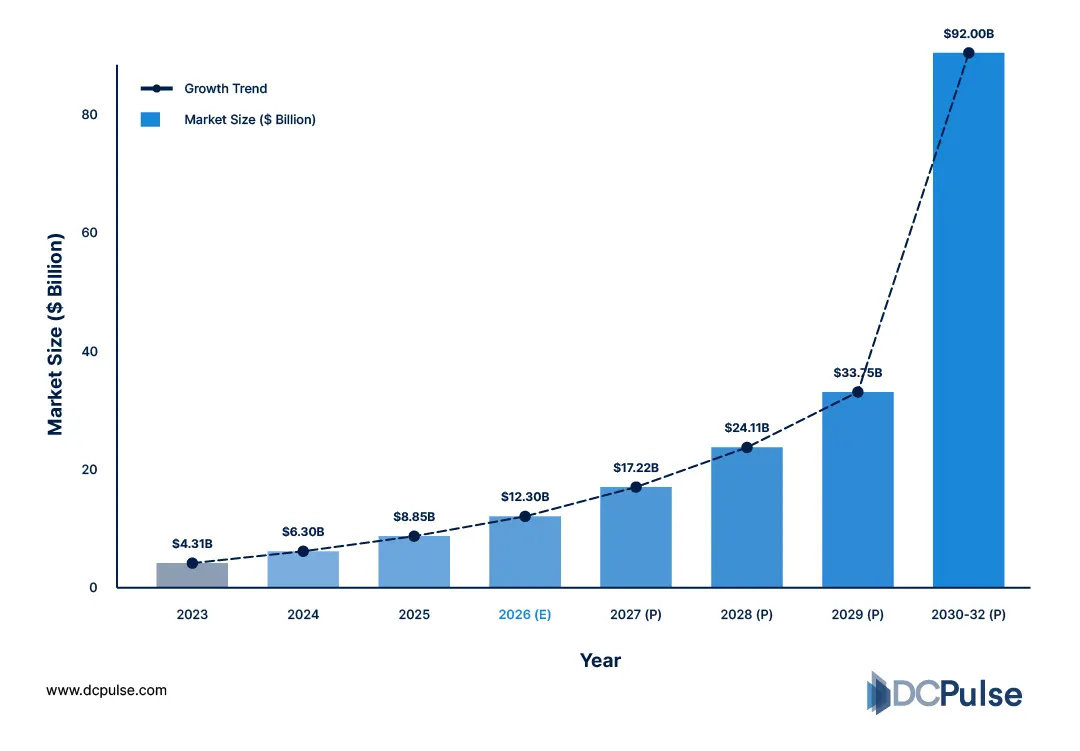
This demand is also creating infrastructure pressure. Reports highlight that rising AI workloads are pushing cloud providers to continuously expand GPU capacity, reinforcing the role of large-scale data centers as the backbone of GPUaaS delivery.
The implication is clear:
GPU-as-a-Service adoption is being driven by a converging ecosystem, where hyperscalers scale globally, specialized providers fill capacity gaps, and market demand, fueled by AI, continues to accelerate infrastructure expansion.
How Will GPU-as-a-Service Shape Future Data Center Demand?
GPU-as-a-Service is set to become one of the primary drivers of data center demand over the next decade.
As AI adoption continues to expand across industries, the need for high-performance compute will grow exponentially. GPUaaS lowers the barrier to access, enabling more organizations to leverage AI without owning infrastructure, ultimately increasing total demand for GPU capacity.
This shift will concentrate demand in large-scale, high-density data centers designed specifically for GPU workloads. These facilities will require significantly higher power, advanced cooling systems, and optimized architectures to support sustained high-performance operations.
At the same time, demand patterns will become more dynamic. Unlike traditional workloads, GPU usage is highly variable, driven by training cycles, inference scaling, and real-time applications. This will require data centers to be more flexible and scalable in how they allocate resources.
However, the impact is not purely about scale. It also changes the nature of infrastructure planning, from steady growth models to bursty, demand-driven expansion strategies.
The direction is clear:
GPU-as-a-Service will not just increase demand; it will reshape how data centers are built, scaled, and operated, making AI-driven compute the central force behind future infrastructure growth.